



顧客分析に基づいてProduct・サービスの訴求点、訴求方法の戦略を決める。
分類後に4象限に分けて、2軸による全体の傾向に対して、グループ毎に全体に対する相対的な位置づけを整理するにも役立ちそう。

tidyclust (K-means)による顧客分析で顧客の特徴を把握、洞察取得。
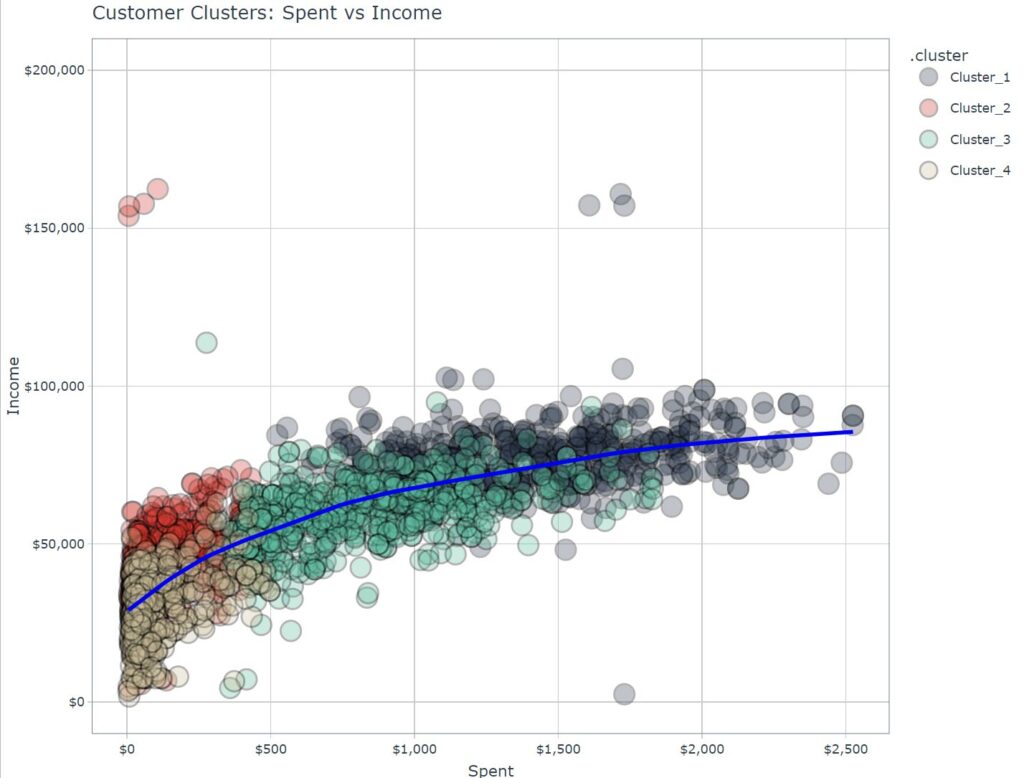
画像に示されている散布図は、「Spent」(支出)と「Income」(収入)の関係を示しており、データがいくつかのクラスターに分かれています。標準化されたデータを扱っている場合、各変数(支出と収入)は平均0、分散1にスケーリングされています。
もしこれらの数値を標準化しないでプロットした場合、以下のような影響が考えられます:
- スケールの不均衡: 支出と収入の変数が異なるスケールを持つ場合、例えば収入が非常に高いスケールであるのに対して支出が比較的小さいスケールの場合、プロットは歪んで表示される可能性があります。この結果、変数間の関係が適切に視覚化されず、特定のパターンが見落とされるかもしれません。
- クラスターの明確さの低下: 現在のプロットでは、クラスターが明確に分離されていますが、標準化をしないと、クラスター間の距離が異なり、境界が不明瞭になる可能性があります。これにより、異なるクラスターの特徴を識別するのが難しくなるでしょう。
- 解釈のしやすさの変化: 標準化されたデータでは、値は単位のないスケールで解釈されますが、標準化されていないデータでは、実際の単位(例えば、ドル)で解釈できるため、解釈が直感的になる可能性があります。しかし、異なるスケールの変数を比較する場合には注意が必要です。
- モデルの性能: 標準化が行われない場合、機械学習モデルのパフォーマンスが悪化する可能性があります。特に、クラスター分析や回帰モデルでは、標準化が変数間の公平な比較を保証し、結果の信頼性を向上させます。
したがって、数値を標準化しないでプロットすると、データの解釈が直感的になる一方で、変数間の比較が難しくなり、クラスターの識別が困難になる可能性があります。

全体像はこんな感じ
# LIBRARIES ----
library(tidymodels)
library(tidyclust)
library(tidyverse) # May need to import library(lubridate)
library(tidyquant)
library(plotly)
# DATA ----
marketing_campaign_tbl <- read_csv("063_tidyclust/data/marketing_campaign.csv")
marketing_campaign_tbl %>% glimpse() %>% View()
# 1.0 DATA PREPARATION ----
data_prep_tbl <- marketing_campaign_tbl %>% # Remove NA values drop_na() %>% # Feature: Customer Age - max customer date(ここではDt_Customer:購入日) mutate(Dt_Customer = dmy(Dt_Customer)) %>% #dmy()とは日付を日月年の形式に変換する関数 mutate(Dt_Customer_Age = -1*(Dt_Customer - min(Dt_Customer) ) / ddays(1) ) %>% # (購入日-最も古い購入日)で期間(difftime型)を示す(数値(numeric)ではない)。 # *-1で負の値に変換(負の値にする事で過去に遡る意味を付与)。 # それを1日で割ることで、日数に変換(difftime型からnumeric型に変換)。 # ddaysは2 つの日付の差を日数で返す関数(数値として扱える) select(-Dt_Customer) %>% #不要な列を削除 # Spent = Sum(Mnt...) mutate(Spent = rowSums(across(starts_with("Mnt")))) %>% # rowSums()は行の合計を計算する関数 # Mntは購入金額を示す列名の接頭辞で商品別ではなくその合計金額の列を作成。 # Remove unnecessary features select(-Z_CostContact, -Z_Revenue, -Response)
data_prep_tbl %>% glimpse() %>% View()
# 2.0 RECIPE ----
recipe_kmeans <- recipe(~ ., data = data_prep_tbl) %>% # recipe()データの前処理を定義する関数 # ~ .は全ての列を選択する事を示す # data = data_prep_tblはデータの指定 step_dummy(all_nominal_predictors(), one_hot = TRUE) %>% # all_nominal_predictors()は全てのカテゴリカル変数を選択する関数 # step_dummy()はカテゴリカル変数をダミー変数に変換する関数 # dummy変数とは0,1で表現される変数の事(数値として扱いやすいようバイナリ列を追加=次元増加) # one_hot = TRUEでone-hotエンコーディング(カテゴリ変数をバイナリ列に変換する事)を行う step_normalize(all_numeric_predictors()) %>% # all_numeric_predictors()は全ての数値変数を選択する関数 step_rm("ID") # ID列を削除する(識別用のラベルであり、クラスタリングへの影響を回避)
recipe_kmeans %>% prep() %>% juice() %>% glimpse() %>% View() # prep()は前処理を実行する関数 # juice()は前処理後のデータを抽出する関数
# 3.0 K-MEANS MODEL ----
model_kmeans <- k_means(num_clusters = 4) %>% # k_means()はk-meansクラスタリングを行う関数 # k_meansクラスタリングとはデータをk個のクラスタに分割する手法 # num_clusters = 4でクラスタ数を4に指定 set_engine("stats") # set_engine()はモデルのエンジンを指定する関数 # モデルのエンジンとはモデルを実行するためのバックエンドの事 # statsは統計モデルを実行するエンジン
set.seed(123)
# set.seed()は乱数のシードを設定する関数
# シードとは乱数の初期値の事で、同じシード(123)を設定すると同じ乱数が生成される
# 乱数の数はここで指定されていないので、乱数の数は無限に生成される
wflw_fit_kmeans <- workflow() %>% # workflow()はデータの前処理、モデルの定義、モデルの適合を一つにまとめる為の関数 # クラスタリングを行うとともに、正規化されたデータと元データの紐づけが行われる add_model(model_kmeans) %>% # add_model()はモデルを追加する関数(定義したk-meansモデルを追加) add_recipe(recipe_kmeans) %>% # add_recipe()は前処理を追加する関数(正規化した実データを追加) # クラスタリングされるのは正規化されたデータ fit(data_prep_tbl) # fit()はモデルを適合させる関数(正規化されたデータと実データの紐づけ) # wflw_fit_kmeansはモデルの適合後のデータを格納する変数で、正規化された各値が4クラスタに分類されている
# 4.0 PREDICT NEW DATA ----
wflw_fit_kmeans %>% predict(data_prep_tbl)
# predict()は新しいデータに対して予測を行う関数
# 実際にはwflw_fit_kmeansの時点で正規化されたデータと実データの紐づけは完了しているものの、明示的にクラスタのラベリングを示す為にpredict関数が使用される。
# この操作をしないと具体的に実データのラベリングを完了できない(まだ内部的に情報を保存)。
extract_cluster_assignment(wflw_fit_kmeans)
# extract_cluster_assignment()はクラスタの割り当てを抽出する関数(dataframe形式で)
# 内部的に保存さている情報(クラスタリング)を抽出する関数
extract_centroids(wflw_fit_kmeans)
# 元のデータセットの各行に対して、そのデータポイントがどのクラスタに属するかを示すクラスタラベルが返されます。
# 返される形式は通常データフレームであり、各データポイントに対応するクラスタ番号が含まれます。
# .cluster列が追加され、クラスタ事に変数の値が整理される。
# 各クラスタがとる変数の値は、各クラスタの重心(centroid)として返されます。
# この重心は各グループにおける変数(正規化された変数)の平均値です。
# BONUS: VISUALIZE CLUSTERS ----
g <- data_prep_tbl %>% # 元々のデータに対して bind_cols(extract_cluster_assignment(wflw_fit_kmeans), .) %>% # bind_cols()はデータフレームを結合する関数 # extract_cluster_assignment()で抽出したクラスタの割り当てを元のデータに追加 # .は結合先の元データ(或いは、直前のデータ:data_prep_tbl)を示す # k-meansクラスタリング作業においても、元のデータフレームの行の順序は保たれ、操作が一貫して行われます。データの信頼性を維持するために、この特性は重要です。 ggplot(aes(Spent, Income)) + # ggplot()はグラフを作成する関数 # aes()はグラフの軸を設定する関数(変数x,変数y) geom_point( # geom_point()は散布図を作成する関数 aes(fill = .cluster), # aes()はグラフの軸を設定する関数(fill = でクラスタの色分け) shape = 21, #shape = 21は点の形状を示す(21は円形) alpha = 0.3, #alpha = 0.3は透明度を示す(0.3は30%透明) size = 5 #size = 5は点のサイズを示す(5は中程度のサイズ) ) + geom_smooth(color = "blue", se = FALSE) + # geom_smooth()は回帰直線を作成する関数 scale_x_continuous(labels = scales::dollar_format()) + # scale_x_continuous()はx軸のラベルを設定する関数 # labels = scales::dollar_format()はx軸のラベルをドル形式に変換する scale_y_continuous( # scale_y_continuous()はy軸のラベルを設定する関数 labels = scales::dollar_format(), limits = c(0, 200000) # limits = c(0, 200000)はy軸の範囲を設定する(0から200000まで) ) + labs(title = "Customer Clusters: Spent vs Income") + # labs()はグラフのタイトルを設定する関数 scale_fill_tq() + # scale_fill_tq()はカラーパレットを設定する関数 theme_tq() # theme_tq()はテーマを設定する関数
ggplotly(g)
# ggplotly()はplotlyのグラフに変換する関数
# plotlyはインタラクティブなグラフを作成するためのパッケージRaw data / Wrangling / Feature Engineering(抽出~整形)
- Source: https://t.co/OZaUuGbfQm
- SQL読込: –
- CSV読込:〇
- CSV

元々のデータフレーム
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
marketing_campaign_tbl <- read_csv("063_tidyclust/data/marketing_campaign.csv")視える化に合わせて編集
追加:Spent、Dt_Customer_Age列

Rのrecipesパッケージを使って、クラスター分析(k-means clustering)用にデータを前処理するためのレシピを定義し、そのレシピを適用してデータを整形するプロセスを示しています。以下は、それぞれのステップの詳細な解説です。
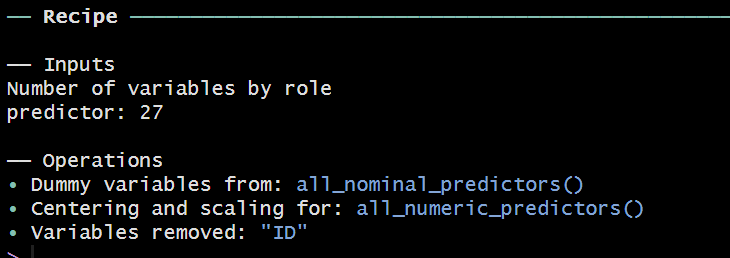
添付された画像は、Rのrecipesパッケージを使用して作成された前処理レシピの概要を示しています。以下は、この画像から読み取れる情報の説明です。
Recipeの概要
- Inputs(入力):
Number of variables by role:predictor: 27
これは、前処理に使用される予測変数の数が27であることを示しています。予測変数とは、モデルの入力として使用される変数のことです。
- Operations(操作):
- Dummy variables from:
all_nominal_predictors()
この操作は、すべての名義変数(カテゴリ変数)をダミー変数に変換するステップを示しています。all_nominal_predictors()は、データセット内のすべての名義変数を指し、それらをワンホットエンコーディングすることが示されています。 - Centering and scaling for:
all_numeric_predictors()
これは、すべての数値予測変数に対してセンタリング(平均を0にする)とスケーリング(標準偏差を1にする)を行うステップです。all_numeric_predictors()は、データセット内のすべての数値変数を指し、それらの変数が正規化されていることを示しています。 - Variables removed:
"ID"
この操作は、データセットから"ID"という名前の変数が削除されたことを示しています。通常、ID列は単なる識別子であり、モデルの学習には不要であるため、削除されることが一般的です。
まとめ
このレシピは、以下の前処理ステップを含んでいます。
- 27個の予測変数が使用されています。
- すべての名義変数がワンホットエンコーディングされてダミー変数に変換されます。
- すべての数値変数がセンタリングとスケーリングの処理を受けます。
- 不要な
ID変数がデータセットから削除されます。
これにより、データが機械学習モデルで効率的に処理できる形に整えられていることがわかります。
1. recipe()関数
recipe_kmeans <- recipe(~ ., data = data_prep_tbl)recipe(~ ., data = data_prep_tbl)は、recipesパッケージのrecipe()関数を使ってデータ処理の「レシピ」を作成するための最初のステップです。~ .はフォーミュラで、data_prep_tblのすべての変数を使用することを示しています。data = data_prep_tblは、前処理の元となるデータセットを指定します。
2. step_dummy()関数
%>% step_dummy(all_nominal_predictors(), one_hot = TRUE)step_dummy(all_nominal_predictors(), one_hot = TRUE)は、データ内のすべてのカテゴリ変数(名義変数(factor型やcharacter型の変数))をワンホットエンコーディングによってダミー変数に変換するステップです。ワンホットエンコーディング(One-Hot Encoding)とは、カテゴリカル(名義)データを機械学習アルゴリズムが扱いやすい数値形式に変換するための手法です。ワンホットエンコーディングでは、各カテゴリごとに新しいバイナリ(0または1の値を持つ)列を作成します。列数が増えるため、分析の精度はがあるものの(数値型として扱える為)、計算負荷が重くなるデメリットがある。all_nominal_predictors()は、名義変数のすべてを対象とします。one_hot = TRUEは、各カテゴリ値ごとに新しいバイナリ列を作成する(ワンホットエンコーディングを行う)ことを指定しています。

3. step_normalize()関数
%>% step_normalize(all_numeric_predictors())step_normalize(all_numeric_predictors())は、数値変数のすべてを正規化するステップです。all_numeric_predictors()は、すべての数値予測変数を対象とします。- 正規化とは、データを平均0、標準偏差1にスケーリングすることで、各変数が同じスケールで扱われるようにします。
4. step_rm()関数
%>% step_rm("ID")step_rm("ID")は、データセットから「ID」列を削除するステップです。- 通常、IDは識別子であり、モデルのトレーニングには使用されないため、削除することが一般的です。
5. prep()関数とjuice()関数
recipe_kmeans %>% prep() %>% juice() %>% glimpse()prep()は、定義したレシピ(recipe_kmeans)を適用し、データを実際に前処理します。prep()は、レシピのステップをデータに適用し、学習用データセットの統計情報を計算します。juice()は、前処理済みのデータを抽出する関数です。この関数を使うと、prep()で前処理された後のデータフレームが返されます。glimpse()は、dplyrパッケージの関数で、データフレームの概要を表示します。変数名、データ型、最初のいくつかの値が表示されます。
全体の流れの要約
- データに対して、ダミー変数の生成、正規化、不要な列の削除などの前処理手順を定義したレシピを作成します。
- レシピを適用してデータを前処理し、前処理されたデータを抽出します。
- 最終的な前処理結果を確認するためにデータの概要を表示します。
この一連の手順により、data_prep_tblという元のデータセットは、k-meansクラスタリングモデルのトレーニングに適した形に変換されます。
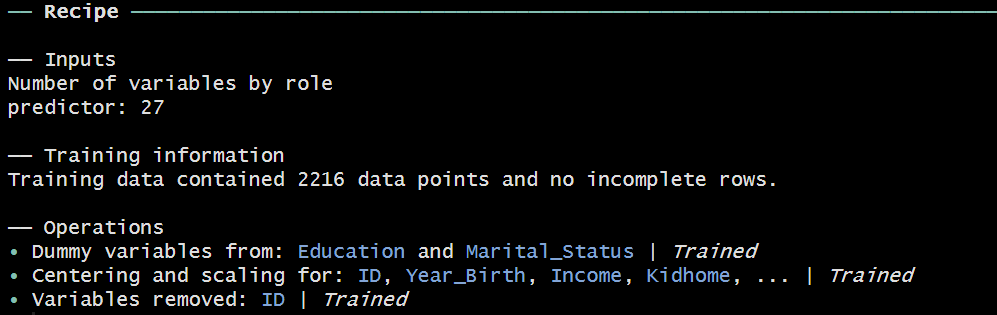
> recipe_kmeans %>% prep()
prep() 前処理(データクレンジング、欠損値の確認)、カテゴリ列からバイナリ列への変換、対象列の正規化が完了。Trainedという表記は、この操作がトレーニングデータに対して適用されたことを意味しています。
トレーニングデータ(training data)とは、機械学習モデルを訓練(学習)させるために使用されるデータセットのことを指します。トレーニングデータを使って、モデルはデータのパターンや関係性を学び、それをもとに将来のデータや未知のデータに対する予測や判断を行うことができるようになります。以下で、トレーニングデータの役割とその関連事項について詳しく説明します。
トレーニングデータの役割
- モデルの学習:
トレーニングデータは、機械学習アルゴリズムがデータのパターンや特徴を学ぶためのデータセットです。モデルは、このデータを通じて予測のルールや関数を作成し、入力データから期待される出力を推定する方法を学びます。 - パラメータの調整:
モデルが最適な予測を行うために、内部のパラメータ(重みやバイアスなど)をトレーニングデータに基づいて調整します。これにより、モデルの性能を向上させることができます。 - 過学習の防止:
トレーニングデータが豊富で適切に選択されていることは、モデルが過学習(トレーニングデータに対しては高い精度を示すが、未知のデータに対しては性能が悪い状態)するのを防ぐためにも重要です。
トレーニングデータとその他のデータセット
機械学習のプロセスでは、データを通常いくつかのセットに分割して使用します。それぞれの役割は以下の通りです。
- トレーニングデータ(Training Data):
- モデルを訓練するために使用されるデータセット。
- モデルはこのデータを使ってパターンや関係性を学びます。
- 検証データ(Validation Data):
- トレーニング中にモデルの性能を評価し、過学習を防ぐために使用されるデータセット。
- モデルのハイパーパラメータの調整や、最適なモデルの選択に役立てます。
- テストデータ(Test Data):
- 最終的にモデルの性能を評価するために使用されるデータセット。
- モデルの評価結果を一般化し、実際の運用環境でのパフォーマンスを予測するために使用します。
- トレーニングと検証に使用されなかったデータを使うことで、モデルの真の精度を確認します。
トレーニングデータにおける Trained の意味
添付画像の「Trained」という表記は、レシピの各ステップがトレーニングデータを基に適用・計算されていることを意味します。具体的には:
- ワンホットエンコーディングの対象となるカテゴリは、トレーニングデータから識別されました。
- 数値変数のセンタリング(平均0)とスケーリング(標準偏差1)の統計量も、トレーニングデータから計算されました。
このように、トレーニングデータに基づいて変換を行うことで、モデルが新しいデータに対して一貫して対応できるようにします。
結論
トレーニングデータは、機械学習モデルがパターンや規則を学習するための基盤となるデータセットです。トレーニングデータを使ってモデルを訓練し、その後、検証データやテストデータを用いてモデルの精度や性能を評価するという手順が一般的に行われます。画像に示される「Trained」という表記は、その操作がトレーニングデータに基づいて適用されたことを意味し、モデルのトレーニングに使用されるデータが適切に処理されていることを示しています。
recipe_kmeans %>% prep() %>% juice() ※ 各種数値は正規化されている。
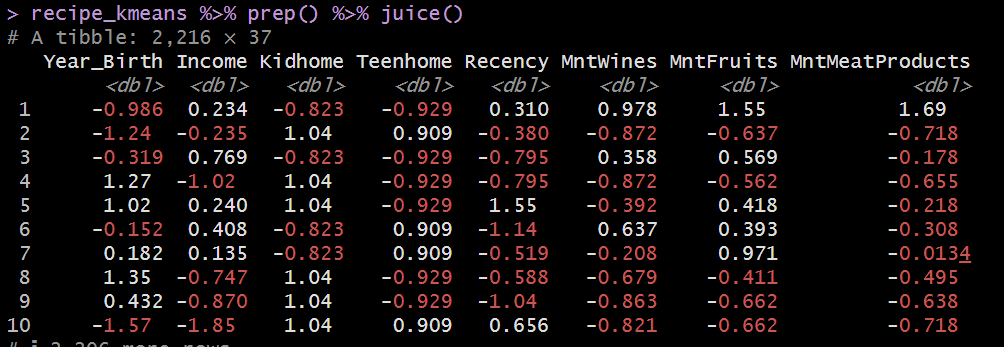
添付された画像は、Rでrecipesパッケージを使って前処理を行った後のデータの一部を示しています。具体的には、recipe_kmeansというレシピを適用した後、prep()で準備を整え、juice()で前処理後のデータを抽出して表示しています。以下、この画像から読み取れる情報を説明します。
データの概要
- データセットのサイズ:
# A tibble: 2,216 x 37
この情報は、データセットが2,216行(データポイント)と37列(特徴量)を持つことを示しています。最初の画像では27個の予測変数がありましたが、前処理によって列が増え、最終的に37個の特徴量になっています。これは、ワンホットエンコーディングによってカテゴリ変数が複数の列に展開された結果です。
- 前処理後のデータの例:
- 表示されているデータには、
Year_Birth,Income,Kidhome,Teenhome,Recency,MntWines,MntFruits,MntMeatProductsなどの列が含まれています。 - これらの値は、標準化されているようです。つまり、平均が0、標準偏差が1になるようにスケーリングされています。標準化は、異なるスケールの数値変数を均一なスケールに揃えることで、機械学習アルゴリズムの効率を向上させるために行われます。
- 数値の見方:
- 例えば、
Year_Birthの最初の値は-0.986です。この値は、標準化後の値であり、元のYear_Birthの値が平均からどれだけ離れているかを示しています。負の値は平均よりも小さいことを意味し、正の値は平均よりも大きいことを意味します。
前処理の目的
- ワンホットエンコーディング:
名義変数がワンホットエンコーディングによって複数のバイナリ列に展開されたため、列数が増加しました。これにより、機械学習アルゴリズムがカテゴリ変数を数値的に処理できるようになります。 - センタリングとスケーリング:
数値変数はセンタリングとスケーリングの操作を受けています。これにより、各数値変数が平均0、標準偏差1の標準化されたスケールで表現されています。標準化は、異なるスケールのデータが同じスケールで比較されるようにするための重要な前処理です。
結論
この画像は、recipe_kmeansレシピによって前処理されたデータの一部を示しており、具体的には次のような処理が行われたことを示しています:
- ワンホットエンコーディングにより、カテゴリ変数が数値列に変換され、列数が増加。
- 数値変数は標準化され、すべての変数が同一のスケールで表現。
- 全体で2,216のデータポイントが処理され、モデルのトレーニングに適した形に整えられている。
これにより、データが機械学習モデルに対して適切に整形され、特にk-meansクラスタリングのようなアルゴリズムで効果的に使用できるようになっています。
k-meansクラスタリングは、機械学習のクラスタリング手法の一つで、データをk個のクラスタ(グループ)に分割する非階層的クラスタリングの手法です。k-meansクラスタリングは、各クラスタ内のデータポイントができるだけ似ているように、そして異なるクラスタのデータポイントができるだけ異なるようにデータを分割することを目指します。
k-meansクラスタリングの基本的な仕組み
- 初期化:
クラスタの数kを事前に指定します。次に、データセットからランダムにk個のデータポイントを選び、これらを初期のクラスタの中心(セントロイド)として設定します。 - 割り当てステップ:
各データポイントを最も近いセントロイドに割り当てます。これにより、データポイントはk個のクラスタに分類されます。距離の計算には一般的にユークリッド距離が使用されます。 - 更新ステップ:
各クラスタのセントロイド(重心)を再計算します。各クラスタ内のデータポイントの平均位置を計算し、それを新しいセントロイドとします。 - 繰り返し:
割り当てステップと更新ステップを繰り返します。データポイントのクラスタ割り当てが変わらなくなるか、セントロイドの位置が変化しなくなるまで(もしくは指定された繰り返し回数に達するまで)続けます。 - 終了:
最終的に、k個のクラスタが形成されます。各クラスタは、類似した特性を持つデータポイントのグループです。
例での理解
考えてみましょう、次のようなデータセットがあるとします:
- 各点は顧客を表し、特徴は年齢と収入です。
- 目標は、顧客を3つのクラスタに分けることです(
k=3)。
- 3つのクラスタ中心をランダムに初期化。
- 各顧客を最も近いクラスタ中心に割り当てる。
- クラスタの中心を再計算(各クラスタ内の顧客の平均年齢と収入を計算)。
- このプロセスを、顧客のクラスタ割り当てが安定するまで繰り返します。
最終的に、類似した顧客が同じクラスタにグループ化され、マーケティング戦略などの用途に活用できます。
k-meansクラスタリングの利点
- シンプルで理解しやすい:
k-meansクラスタリングは非常に直感的で、計算も比較的シンプルです。 - 計算が高速:
他のクラスタリング手法と比較して計算が速く、大規模データセットでも実用的です。
k-meansクラスタリングの欠点
- クラスタの数を事前に指定する必要がある:
適切なkの値を決めるためには試行錯誤が必要であり、特に未知のデータに対しては難しいことがあります。 - 初期値に依存:
最初に選んだセントロイドの位置によって結果が異なることがあります。異なる初期化で複数回実行し、最良の結果を選ぶことが一般的です。 - 非球状のクラスタに対する弱さ:
k-meansは球状のクラスタには効果的ですが、非球状のクラスタには対応が難しいことがあります。
まとめ
k-meansクラスタリングは、データをk個のクラスタに分割するためのシンプルで効果的な手法です。シンプルでありながら、顧客セグメンテーション、パターン認識、異常検出など多くの応用が可能です。ただし、クラスタの数の選択や初期化の敏感さといった点には注意が必要です。
ユークリッド距離と最小二乗法は、どちらも数学的な測定と最適化の方法ですが、異なる目的と文脈で使用されます。以下で、それぞれの違いと関係性について説明します。
ユークリッド距離とは
ユークリッド距離は、2つの点の間の「直線距離」を計算する方法です。これは、クラスタリングや距離ベースの分類(例えば、k-最近傍法)などで使われ、データポイント間の類似性を測定するために使用されます。ユークリッド距離は、特定の点から他の点までの「物理的な距離」を求めることに直感的に対応しています。
最小二乗法とは
最小二乗法(Least Squares Method)は、統計モデルにおいて観測データとモデルの予測値の間の差異(誤差)を最小化するための方法です。具体的には、データポイントの観測値とモデルの予測値の差の二乗和を最小にするようにモデルのパラメータを調整します。これは、回帰分析(線形回帰や非線形回帰など)で広く使用されます。
最小二乗法の基本的な目的は、以下のように定義されます:
- 観測データ:( (x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n) )
- モデル:( y = f(x, \beta) )(ここで ( \beta ) はモデルのパラメータ)
最小二乗法は、以下の二乗和を最小化するパラメータ ( \beta ) を見つけることです:
[
\text{minimize } \sum_{i=1}^{n} (y_i – f(x_i, \beta))^2
]
ユークリッド距離と最小二乗法の関係
- 誤差の測定方法:
- 最小二乗法では、モデルの予測値と観測値の間の差(誤差)を二乗して合計し、その合計を最小化します。この誤差の二乗和は、ユークリッド距離の概念に基づいています。
- 観測値と予測値の差を二乗することで、正負にかかわらず誤差を正の値として扱い、さらに大きな誤差に対してより大きなペナルティを与えることができます。
- 幾何学的解釈:
- 最小二乗法において、誤差の二乗和を最小化することは、データポイントからモデルの予測値への「ユークリッド距離」を最小化することと解釈できます。このため、最小二乗法はデータポイントが線上に最も近づくように調整されます。
- 共通点:
- 両者とも、何らかの意味で「距離」を測定し、それを最小化するという目標を持っています。ユークリッド距離は、単に2点間の直線距離であり、最小二乗法はモデル全体の予測精度を最適化するための誤差の合計距離を最小にする方法です。
まとめ
- ユークリッド距離は、2つの点間の物理的な直線距離を測る方法であり、クラスタリングや距離ベースの分析に使用されます。
- 最小二乗法は、モデルの予測値と実際の観測値の間の誤差を最小化するための統計的手法であり、回帰分析で広く使用されます。
- 最小二乗法における誤差の最小化は、幾何学的にはユークリッド距離の最小化と関連がありますが、目的とコンテキストが異なるため、同じものとは言えません。
このように、ユークリッド距離と最小二乗法は異なる目的で使用されるものの、距離の概念を用いてデータ間の関係性を評価するという点では共通しています。
はい、理解はほぼ正しいです。model_kmeans <- k_means(num_clusters = 4) %>% set_engine("stats")というスクリプトは、Rでk-meansクラスタリングを実行するためのモデルを設定していることを意味します。ここで、バックエンドのエンジンの意味と、その設定についてもう少し具体的に説明します。
バックエンドのエンジンとは
- バックエンドのエンジン:
モデルを実行する際の計算を実際に行うプログラムやライブラリを指します。Rでは、同じ種類のモデル(ここではk-meansクラスタリング)でも、異なる実装やパッケージを使用して計算を行うことができます。set_engine()関数を使って、どのエンジンを使用するかを指定することができます。 statsエンジン:
Rの標準パッケージstatsに含まれるkmeans()関数を利用してk-meansクラスタリングを実行します。statsパッケージはRに標準で含まれており、広く使用されています。このエンジンを使うことで、信頼性の高い標準的なk-meansクラスタリングの計算が行われます。
スクリプトの動作の詳細
k_means(num_clusters = 4):
- これは、
tidymodelsパッケージの一部として提供される高水準な関数で、k-meansクラスタリングを設定するためのものです。 num_clusters = 4により、データを4つのクラスタに分割するように指定しています。
%>%(パイプ演算子):
- パイプ演算子は、前の関数の結果を次の関数に渡すために使用されます。ここでは、
k_means()で定義したモデルの設定を、set_engine()に渡しています。
set_engine("stats"):
- この部分は、k-meansクラスタリングの計算を実行するための具体的なエンジン(実装)として
statsを選んでいることを示します。 statsは、Rのベースパッケージで、基本的な統計計算を提供します。kmeans()関数もこのパッケージに含まれています。- ここで
statsを指定することで、stats::kmeans()関数が裏で呼び出され、k-meansクラスタリングの計算が行われることになります。
結論
- 「バックエンドのエンジン」という言葉は、モデルを実際に計算・実行するための具体的な関数やライブラリのことを指しています。Rでは、このようなエンジンを
set_engine()関数で明示的に指定することで、どのライブラリの実装を使うかをコントロールできます。 - このスクリプトは、Rの
tidymodelsフレームワーク内でk-meansクラスタリングモデルを定義し、その計算をRの標準的なstatsパッケージのk-means実装を使って行うように設定していることを意味します。
このように理解していただいて問題ありません。
このコードは、Rのtidymodelsフレームワークを使用して、k-meansクラスタリングモデルをデータに適合させるためのワークフローを定義・実行する手順を示しています。ここで使用されている関数は、データの前処理、モデルの定義、そしてモデルの適合(フィッティング)を一連のプロセスとしてまとめて実行するために使用されます。以下、それぞれの部分が何をしているのかを詳しく説明します。
コードの詳細
workflow():
workflow()関数は、tidymodelsパッケージの一部で、データの前処理、モデルの定義、モデルの適合を一つにまとめるためのオブジェクト(ワークフロー)を作成します。ワークフローは、モデルの構築プロセスを体系的に管理するために使用されます。- これにより、前処理ステップとモデルの定義を一元管理し、コードの読みやすさや保守性を向上させます。
add_model(model_kmeans):
add_model()関数は、作成したワークフローにモデルを追加するために使用されます。- ここでは、事前に定義されたk-meansクラスタリングモデル(
model_kmeans)をワークフローに追加しています。model_kmeansは、4つのクラスタを生成するk-meansモデルです。
add_recipe(recipe_kmeans):
add_recipe()関数は、作成したワークフローに前処理のレシピを追加するために使用されます。- ここでは、事前に定義された前処理のレシピ(
recipe_kmeans)をワークフローに追加しています。recipe_kmeansは、データのダミー変数化、正規化、ID列の削除などの前処理ステップを定義しています。
fit(data_prep_tbl):
fit()関数は、ワークフローにデータを適用して、モデルを適合させる(フィッティングする)ために使用されます。- ここでは、
data_prep_tblというデータセットを使用して、定義された前処理レシピとモデルを適用し、k-meansクラスタリングを実行します。 - このステップで、実際のクラスタリングが行われ、データが4つのクラスタに分割されます。
全体の流れのまとめ
- ワークフローの作成:
workflow()を使ってワークフローオブジェクトを作成します。このワークフローは、データの前処理とモデルの適合を一元管理するためのものです。
- モデルの追加:
add_model(model_kmeans)を使って、k-meansクラスタリングモデル(4つのクラスタを生成する設定)をワークフローに追加します。
- 前処理レシピの追加:
add_recipe(recipe_kmeans)を使って、データの前処理を定義したレシピをワークフローに追加します。これにより、データの標準化やカテゴリ変数のエンコーディングが含まれます。
- モデルの適合:
fit(data_prep_tbl)を使って、前処理されたデータセットをk-meansクラスタリングモデルに適合させます。これにより、データがクラスタに分割され、クラスタリングの結果が得られます。
結論
このコードは、k-meansクラスタリングを実行するための一連の手続きをtidymodelsフレームワーク内で管理するために、ワークフローを使用してモデルの定義、データの前処理、モデルの適合を行っています。これにより、モデル構築プロセスが体系的で、再利用可能な形で管理され、データ分析や機械学習のワークフローが整理されて実行されることを示しています。
はい、その理解は正しいです。wflw_fit_kmeansの時点で、ワークフローに含まれる前処理レシピとk-meansクラスタリングモデルを用いて、実データ(data_prep_tbl)とクラスタリング結果の紐付けが完了しています。しかし、wflw_fit_kmeans自体は、その内部にどのデータポイントがどのクラスタに属しているかの情報を持っているものの、その情報を明示的に表示するにはpredict()関数を使って結果を抽出する必要があります。
詳細な解説
wflw_fit_kmeansの状態:
wflw_fit_kmeansは、前処理とクラスタリングが適用された後の状態を保持するワークフローオブジェクトです。この時点で、k-meansクラスタリングの計算が完了しており、各データポイントがどのクラスタに属するかの情報も内部に保持されています。- ただし、
wflw_fit_kmeansオブジェクト単体では、クラスタ割り当ての結果が明示的に表示されているわけではありません。このオブジェクトは、前処理されたデータとそれに基づいたモデルの適合状態を持っている「状態の保持」をしているだけです。
predict()関数の役割:
predict(wflw_fit_kmeans, data_prep_tbl)を呼び出すことで、実際にどのデータポイントがどのクラスタに割り当てられたかが明示的に表示されます。predict()関数は、wflw_fit_kmeansオブジェクトを使って、data_prep_tblデータに対して予測を行い、各データポイントのクラスタラベルを出力します。これにより、クラスタリング結果が具体的に見える形で表現されます。
まとめ
wflw_fit_kmeansの時点で、モデルは実データに適合され、各データポイントがどのクラスタに属するかの内部的な状態を保持しています。predict()関数を使うことで、その内部状態を明示的に外部に表示し、各データポイントがどのクラスタに属しているかを確認できます。- つまり、
wflw_fit_kmeansはクラスタリングの情報を保持しているが、その情報を外部に表示するためにはpredict()が必要です。predict()の結果は、各データポイントがどのクラスタに割り当てられたかを具体的に示し、クラスタリングの結果を明確に可視化します。
このように、ワークフローによって前処理とクラスタリングの適用が完了している状態をwflw_fit_kmeansが保持しており、その状態を利用してpredict()で明示的なクラスタリング結果を得るという流れになります。
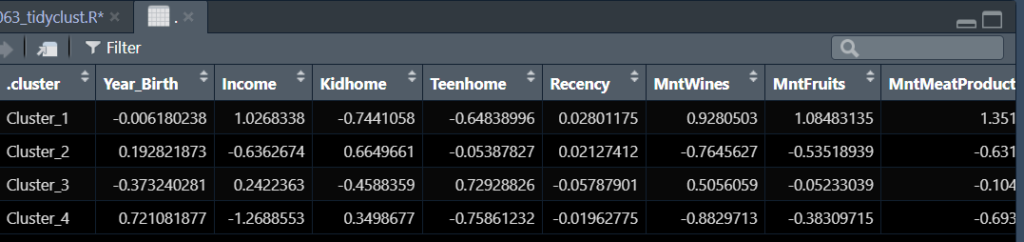
extract_centroids(wflw_fit_kmeans)で以下のようにクラスター(グループ)毎に情報が纏められる。各値は各グループの正規化された値の平均値。
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。
- 値:data point、Feature
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

