



Conductor
group_by() % summarise(across(c(変数1,変数2), .fns = list(“mean” = ~ mean(.x), “range lo” = ~ mean(.x) – 2*sd(.x), “range hi” = ~ mean(.x) + 2sd(.x)))) ← この形で覚えてしまう。

Visualizer
今回はスキップ。目的に応じてカラムとして集計する変数を追加していく。

Wrangler
全体像はこんな感じ
# 1.0 BASIC USAGE ----
# * AVERAGE CITY FUEL CONSUMPTION BY VEHICLE CLASS ----
mpg %>% group_by(class) %>% summarise( across(cty, .fns = mean), # .fns = mean で平均値を計算 # .fns = とはfunctionの略 # across() で指定したカラムに対してfunctionを適用 .groups = "drop" # .groups = "drop" でgroup_by()の効果を無効化、つまり通常のテーブルに戻す。 # グループ化されたままにする場合(group_by()の効果を残す場合)、".groups = "keep""を指定。 # または、group_by()の代わりにgroup_by()の代わりにungroup()を使う。 # .group_by()を残してしまうと、その後の処理でエラーが発生することがある。 # group_by()の効果が残っていると、group_by()で指定したカラム以外のカラムを使うとエラーが発生する。 )
# * AVERAGE & STDEV CITY FUEL CONSUMPTION BY VEHICLE CLASS
mpg %>% group_by(class) %>% summarise( across(cty, .fns = list(mean = mean, stdev = sd)), .groups = "drop" # acrossはlist()で複数のfunctionを指定できる。(複数列の設定) # 列名はmeanとstdevになる。接頭辞のctyは自動で各列に付与される。 )
# * AVERAGE & STDEV CITY + HWY FUEL CONSUMPTION BY VEHICLE CLASS
mpg %>% group_by(class) %>% summarise( across(c(cty, hwy), .fns = list(mean = mean, stdev = sd)), .groups = "drop" # 複数変数も指定可能 )
# 2.0 ADVANCED ----
# * CUSTOMIZE NAMING SCHEME ----
mpg %>% group_by(class) %>% summarise( across( c(cty, hwy), .fns = list(mean = mean, stdev = sd), .names = "{.fn} {.col} Consumption" # .names = "{.fn} {.col} Consumption" で列名をカスタマイズ # Consumptionは固定 # .fn はfunction名、.col は列名 # .fnsはlist()で指定する。複数のfunctionを指定できる。 # この場合、列名は "mean cty Consumption" と "stdev cty Consumption" になる。 ), .groups = "drop" ) %>% rename_with(.fn = str_to_upper) # rename_with() で列名を大文字に変換 # str_to_upper() で大文字に変換 # rename_with(.fn = str_to_upper) で全ての列名を大文字に変換 # .fn はfunction名。functionとは、列名を変更するfunctionを指定する。
# * COMPLEX FUNCTIONS ----
mpg %>% group_by(class) %>% summarise( across( c(cty, hwy), .fns = list( "mean" = ~ mean(.x), # ~ はfunction(無名関数)の略. .x は列名。ここではc()で指定した列名。 "range lo" = ~ (mean(.x) - 2*sd(.x)), # 平均値から2標準偏差を引いた値(下限)。全データの95%がこの範囲に収まる。 "range hi" = ~ (mean(.x) + 2*sd(.x)) # 平均値から2標準偏差を足した値(上限)。全データの95%がこの範囲に収まる。 ), .names = "{.fn} {.col}" # 列名をカスタマイズ ), .groups = "drop" ) %>% rename_with(.fn = str_to_upper)Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: https://fueleconomy.gov/
- SQL読込: –
- CSV読込: –
- API読込 : 〇(mpg)
- rmarkdown:render()読込:- (.rmdのファイルをtemlate保存しておく必要あり)

Extractor
元々のデータフレーム(mpg)
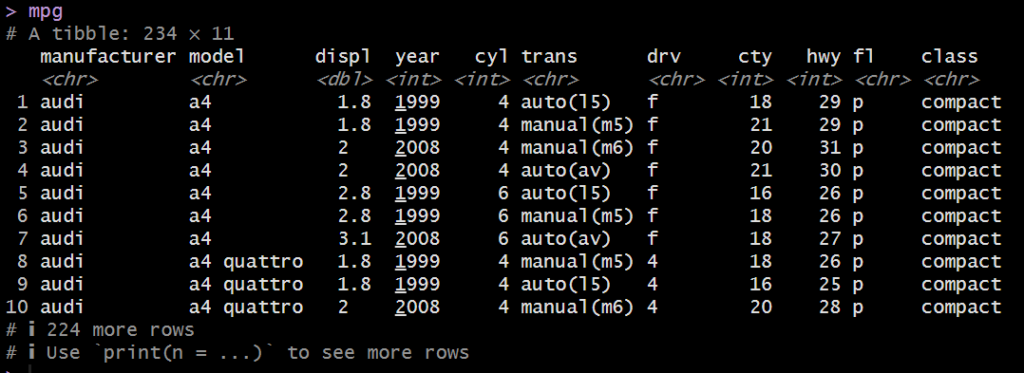
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
mpgWrangler
視える化に合わせて編集
特になし。
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。.xは列を指定している。
- 値:data point、Feature
- Wide format:クロス集計表(横持ちデータ)、Long format:縦持ちデータ
- 情報ソースがWEBサイト(HTMLやCSS)の場合にはどこから抽出するか、が問われるので、HTMLやCSSの知識が必要(スクレイピングを実施するにせよ)。
- レンダリング(rendering)とはコンピュータがデータを処理して画像や映像、テキストなどを表示させる技術。
- .fn(単数)と.fns(複数)はfunctionの略で無名関数。~ (tilde:チルダ) も無名関数。
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

