



Conductor
複数ファイルのCSVファイルの読み込み

Visualizer
これは実務上は大事かも
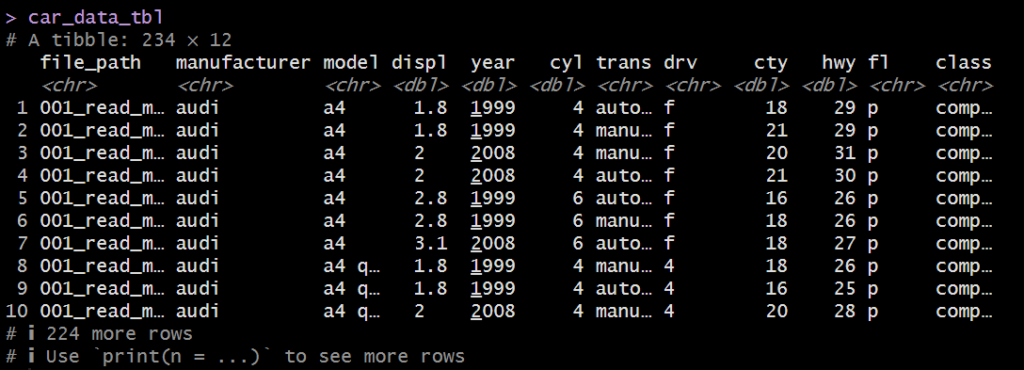
file_pathの列を追加。

Wrangler
全体像はこんな感じ
# 1.0 LIBRARIES ----
library(tidyverse)
library(fs)
# 2.0 READING MULTIPLE CSV ----
# - Tip 001 - Revised to specify column types
# - FIXES Error: Can't combine `drv` <character> and `drv` <logical>.
directory_that_holds_files <- "001_read_multiple_files/data/"
car_data_list <- directory_that_holds_files %>% dir_ls() %>% # dir_ls()とは指定したディレクトリ内のファイルをリストで取得する関数。 map( .f = function(path) { #.fとはmap関数の引数で、各要素に適用する関数を指定する。 # function(path)は各要素に適用する関数を指定している。 # path は、dir_ls() でリストされた各CSVファイルのパス。 # リスト化されたpathの先のファイルのカラムの読込指定。 read_csv( path, col_types = cols( manufacturer = col_character(), model = col_character(), displ = col_double(), year = col_double(), cyl = col_double(), trans = col_character(), drv = col_character(), cty = col_double(), hwy = col_double(), fl = col_character(), class = col_character() ) ) } )
# 3.0 BINDING DATA FRAMES ----
# - bind_rows() : Taught in DS4B 101-R
car_data_tbl <- car_data_list %>% set_names(dir_ls(directory_that_holds_files)) %>% # car_data_list の各データフレームに対して、dir_ls(directory_that_holds_files) で取得したファイルパスを名前として付与します。 # これにより、ファイルパスがリストの名前として設定されます。 # bind_rows() は、リスト内の複数のデータフレームを行方向に結合します。 # この際、.id 引数を指定することで、どのデータフレームがどのファイルから読み込まれたかを示す列(ここでは file_path 列)を作成します。 bind_rows(.id = "file_path")
car_data_tbl
# 4.0 CREATE A DIRECTORY ----
# - fs package
new_directory <- "004_writing_multiple_files/car_data_01/"
# pathを記載。
dir_create(new_directory)
# directory_that_holds_files とは異なるディレクトリを作成します。
# 5.0 SPLITTING & WRITING CSV FILES ----
# - Text (stringr): Taught in DS4B 101-R
# - Iteration (purrr map): Taught in DS4B 101-R
car_data_tbl %>% mutate(file_path = file_path %>% str_replace(directory_that_holds_files, new_directory)) %>% # file_path に含まれる directory_that_holds_files を new_directory に置換します。 # str_replace() は、文字列の置換を行います。 group_by(file_path) %>% # file_path でグループ化します。 group_split() %>% # group_split() は、グループ化されたデータフレームをリストに変換します。 map( .f = function(data) { write_csv(data, path = unique(data$file_path)) # write_csv() は、データフレームをCSVファイルとして書き込みます。 # path 引数には、書き込むファイルのパスを指定します。 # unique(data$file_path) は、dataのfile_path列のユニークな値を取得します。 } )Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: CSVファイル格納
- SQL読込: –
- CSV読込: 〇
- API読込 : –

Extractor
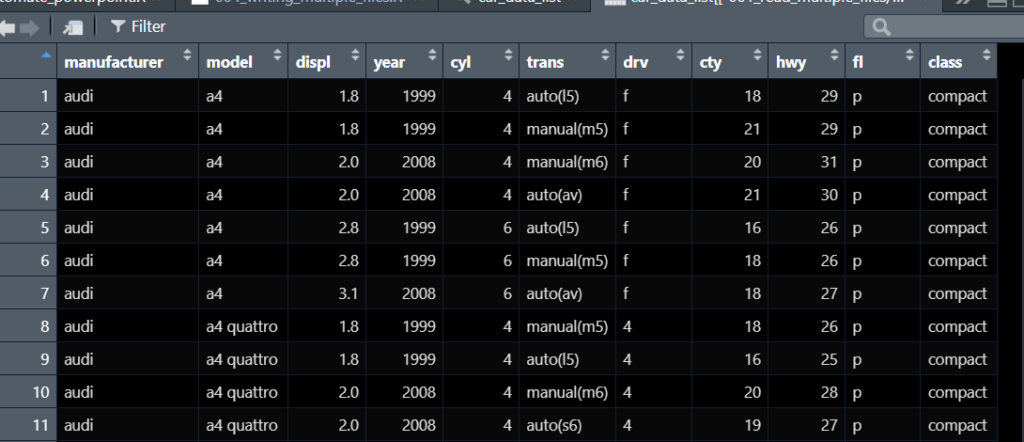
元々のデータフレーム
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
`read_csv()` 関数の `path` 引数は、読み込みたいCSVファイルの**ファイルパス**を指定するための引数です。ファイルパスは、コンピュータのどこにそのファイルが存在するかを示すもので、`read_csv()` はそのパスを基にファイルを見つけてデータを読み込みます。
例えば、`read_csv("data/sample.csv")` のように、`path` に `"data/sample.csv"` を渡すと、`read_csv()` はそのパスにある `sample.csv` ファイルを開いて読み込みます。
### ファイルパスの種類
1. **絶対パス**: ルートディレクトリから始まる完全なパス。 - 例: `C:/Users/username/Documents/data/sample.csv`
2. **相対パス**: 現在の作業ディレクトリを基準としたパス。 - 例: `data/sample.csv` (現在のディレクトリ内の `data` フォルダにある `sample.csv` を指す)
### コード内での `path` の役割
コード内の `map(.f = function(path) {...})` の `path` は、`dir_ls()` で取得されたファイルパスのリストから1つずつ渡されます。そのため、各CSVファイルのパスが `read_csv()` に渡され、それぞれのCSVファイルが順に読み込まれる仕組みです。
```r
map( .f = function(path) { read_csv(path, ...) }
)
```
この `path` は、`dir_ls()` でリストされた各CSVファイルのパスです。Wrangler
視える化に合わせて編集
スキップ
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。
- 値:data point、Feature
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

