



Conductor
rmarkdown:render()の読込まで(生データの作成は別の機会で)

Visualizer
PDFを指定してアウトプット

Wrangler
全体像はこんな感じ
# 1.0 LIBRARIES ----
library(rmarkdown)
# 2.0 AUTOMATE PDF REPORTING ----
# - Make sure you have tinytex installed with: tinytex::install_tinytex()
install.packages("tinytex")
library(tinytex)
# Technology Portfolio ----
portfolio_name <- "Technology Portfolio"
symbols <- c("AAPL", "GOOG", "NFLX", "NVDA")
output_file <- "technology_portfolio.pdf"
# Financial Portfolio ----
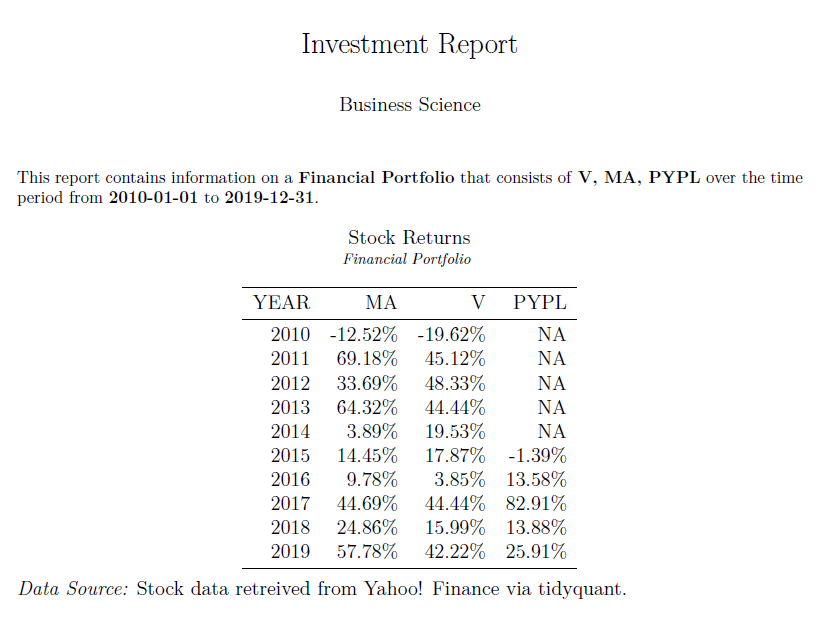
portfolio_name <- "Financial Portfolio"
symbols <- c("V", "MA", "PYPL")
output_file <- "financial_portfolio.pdf"
# Automation Code ----
rmarkdown::render( # render() 関数は、R Markdown ファイルをレンダリングします。 # render(input, output_format, output_file, output_dir, params) input = "007_pdf_reporting/template/stock_report_template.Rmd", # input: レンダリングするR Markdownファイルのパス # レンダリングとは、R MarkdownファイルをHTML、PDF、Wordなどのファイル形式に変換することです。 # 前提として、R Markdownファイルは、事前に作成する必要性がある。 output_format = "pdf_document", # output_format: レンダリングするファイル形式を指定します。 output_file = output_file, # output_file: レンダリングされたファイルの名前を指定します。 # ここでは変数output_fileに格納されたファイル名を指定しています。 output_dir = "007_pdf_reporting/output/", # output_dir: レンダリングされたファイルの保存先ディレクトリを指定します。 # params: レンダリング時に使用するパラメータを指定します。 # list 関数を使用して、portfolio_name、symbols、start、end、show_codeのパラメータを指定しています。 params = list( portfolio_name = portfolio_name, # portfolio_name: ポートフォリオ名を指定します。 symbols = symbols, # symbols: シンボルを指定します。 start = "2010-01-01", # start: 開始日を指定します。 end = "2019-12-31", # end: 終了日を指定します。 show_code = FALSE # show_code: コードを表示するかどうかを指定します。 )
)Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: Yahoo finance
- SQL読込: –
- CSV読込: –
- API読込 : 〇
- rmarkdown:render()読込:- (.rmdのファイルをtemlate保存しておく必要あり)

Extractor
元々のデータフレーム(.rmdファイルを作成する必要がある)
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
# Automation Code ----
rmarkdown::render( # render() 関数は、R Markdown ファイルをレンダリングします。 # render(input, output_format, output_file, output_dir, params) input = "007_pdf_reporting/template/stock_report_template.Rmd", # input: レンダリングするR Markdownファイルのパス # レンダリングとは、R MarkdownファイルをHTML、PDF、Wordなどのファイル形式に変換することです。 # 前提として、R Markdownファイルは、事前に作成する必要性がある。 output_format = "pdf_document", # output_format: レンダリングするファイル形式を指定します。 output_file = output_file, # output_file: レンダリングされたファイルの名前を指定します。 # ここでは変数output_fileに格納されたファイル名を指定しています。 output_dir = "007_pdf_reporting/output/", # output_dir: レンダリングされたファイルの保存先ディレクトリを指定します。 # params: レンダリング時に使用するパラメータを指定します。 # list 関数を使用して、portfolio_name、symbols、start、end、show_codeのパラメータを指定しています。 params = list( portfolio_name = portfolio_name, # portfolio_name: ポートフォリオ名を指定します。 symbols = symbols, # symbols: シンボルを指定します。 start = "2010-01-01", # start: 開始日を指定します。 end = "2019-12-31", # end: 終了日を指定します。 show_code = FALSE # show_code: コードを表示するかどうかを指定します。 )
)Wrangler
視える化に合わせて編集
特になし。
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。
- 値:data point、Feature
- Wide format:クロス集計表(横持ちデータ)、Long format:縦持ちデータ
- 情報ソースがWEBサイト(HTMLやCSS)の場合にはどこから抽出するか、が問われるので、HTMLやCSSの知識が必要(スクレイピングを実施するにせよ)。
- レンダリング(rendering)とはコンピュータがデータを処理して画像や映像、テキストなどを表示させる技術。
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

