



Conductor
時系列で、集計の方法、期間を決める。

Visualizer
時系列、2列で、株価をプロット。


Wrangler
全体像はこんな感じ
# 1.0 LIBRARIES ----
library(officer)
library(flextable)
library(tidyverse)
library(tidyquant)
library(timetk)
# 2.0 DATA ----
# - Use tidyquant to pull in some stock data
stock_data_tbl <- c("AAPL", "GOOG", "META", "NVDA") %>% tq_get(from = "2019-01-01", to = "2020-08-16")
# tq_get(from = "2019-01-01", to = "2020-08-16"): これは、tidyquant パッケージの関数で、
# 指定した期間(ここでは2019年1月1日から2020年8月16日まで)の株価データを取得します。
# tq_get() 関数はデフォルトで yahoo フィナンシャルデータAPIを使用してデータを取得しますが、
# 他のソースも指定することができます。
# 3.0 DATA WRANGLING ----
# - dplyr (DS4B 101-R Weeks 2 & 3)
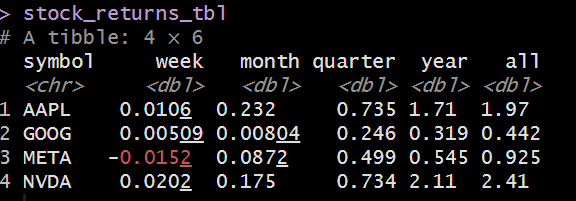
stock_returns_tbl <- stock_data_tbl %>% select(symbol, date, adjusted) %>% group_by(symbol) %>% summarise( week = last(adjusted) / first(tail(adjusted, 7)) - 1, month = last(adjusted) / first(tail(adjusted, 30)) - 1, quarter = last(adjusted) / first(tail(adjusted, 90)) - 1, year = last(adjusted) / first(tail(adjusted, 365)) - 1, all = last(adjusted) / first(adjusted) - 1 ) # last() 関数は、最後の値を取得します。 # tail() 関数は、指定した変数の最後の値を取得します。 # 変数列の最後の7日間の数値を取得(adjusted列の、後ろから7つの数値をピック)。 # first() 関数は、最初の値を取得します。7日間の内、最初の値を取得。 # つまり7日前の数値を抽出して、直近の株価を割っています。増減比が出ている。
# 4.0 PLOTS & TABLES ----
# - ggplot2 (DS4B 101-R Weeks 4)
# * Stock Plot ----
stock_plot <- stock_data_tbl %>% group_by(symbol) %>% summarize_by_time(adjusted = AVERAGE(adjusted), .by = "week") %>% # summarize_by_time() 関数は、指定した期間でデータを集計します。週次(7日間)毎に集計。 plot_time_series(date, adjusted, .facet_ncol = 2, .interactive = FALSE) # plot_time_series() 関数は、時系列データをプロットします。 # .facet_ncol = 2 は、2列でプロットすることを指定しています(グラフ画面)。 # .interactive = FALSE は、インタラクティブなプロットを無効にしています。 # インタラクティブなプロットとは、時系列フィルタリング、対象時間の移動、ズームイン、ズームアウト、Export。 # plot_time_series(.date_var = date, adjusted, .facet_ncol = 2, .interactive = FALSE)
stock_plot
# * Stock Return Table -----
stock_table <- stock_returns_tbl %>% rename_all(.funs = str_to_sentence) %>% # rename_all() 関数は、列名を変更します。 # .funsは、列名を変更する関数を指定します。ここでは、str_to_sentence() 関数を指定しています。 # str_to_sentence() 関数は、列名をCamel CaseからSnake Caseに変更します(大文字小文字の組み合わせ、と、under scoreで区切る)。 mutate_if(is.numeric, .funs = scales::percent) %>% # mutate_if() 関数は、指定した条件に基づいて列(内容)を変更します。 # is.numeric は、数値列を指定しています。 # .funs = scales::percent は、数値列をパーセントに変換します。 flextable::flextable() # flextable() 関数は、表を作成します。
stock_table
# 5.0 MAKE A POWERPOINT DECK -----
doc <- read_pptx() # read_pptx() 関数は、空のPowerPointスライドを作成します。
doc <- add_slide(doc) # add_slide() 関数は、スライドを追加します。
doc <- ph_with(doc, value = "Stock Report", location = ph_location_type(type = "title"))
# ph_with() 関数は、スライドにテキストを追加します。
# value = "Stock Report" は、スライドに追加するテキストを指定しています。
# location = ph_location_type(type = "title") は、テキストの位置を指定しています。
# ph_location_type(type = "title") は、タイトルの位置を指定しています。
doc <- ph_with(doc, value = stock_table, location = ph_location_left())
# ph_with() 関数は、スライドにテーブルを追加します。
# value = stock_table は、スライドに追加するテーブルを指定しています。
# location = ph_location_left() は、テーブルの位置を指定しています。
# ph_location_left() は、テーブルの位置を左に指定しています。
doc <- ph_with(doc, value = stock_plot, location = ph_location_right())
print(doc, target = "003_powerpoint_slidedeck/stock_report.pptx")
# print() 関数は、PowerPointスライドを出力します。Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: tq_get() 関数はデフォルトで yahoo フィナンシャルデータAPIを使用してデータを取得
- SQL読込: –
- CSV読込: –
- API読込 :〇
- API

Extractor
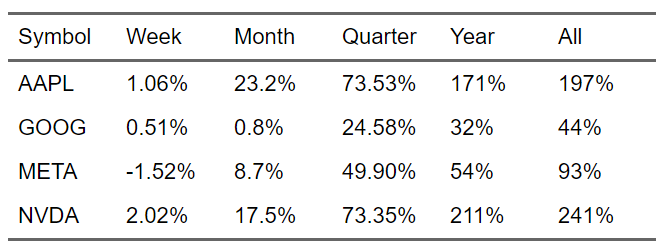
元々のデータフレーム
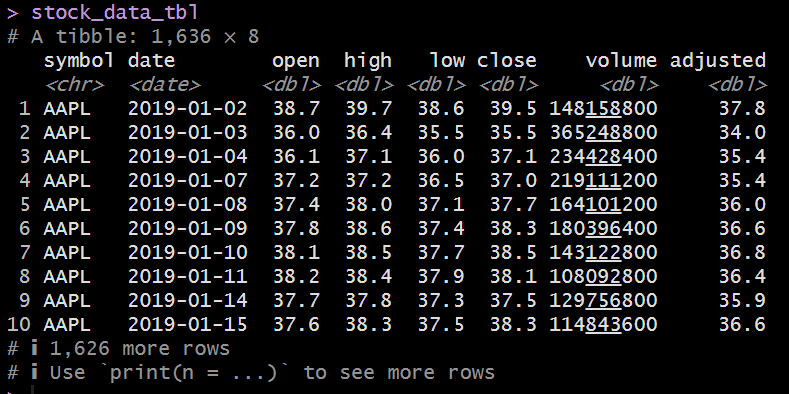
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
stock_data_tbl <- c("AAPL", "GOOG", "META", "NVDA") %>% tq_get(from = "2019-01-01", to = "2020-08-16")Wrangler
視える化に合わせて編集
追加:各symbol別に各集計期間の数値を記載
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。
- 値:data point、Feature
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

