Scraping Word Docs

全体像はこんな感じ
source: https://www.business-science.io/
# 1.0 LIBRARIES ----
library(officer)
library(janitor)
library(ggtext)
library(tidyverse)
# 2.0 EXTRACT THE DOCX CONTENTS -----
doc <- read_docx("002_scraping_word_docs/Business Science.docx")
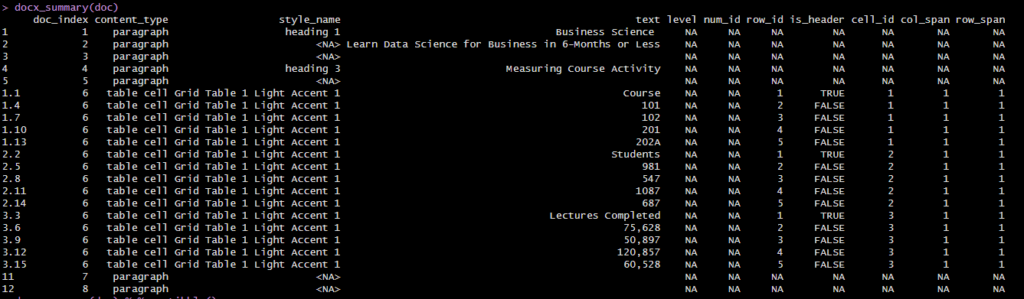
content_tbl <- docx_summary(doc) %>% as_tibble()
table_content_tbl <- content_tbl %>% filter(content_type == "table cell")
table_content_tbl
# 3.0 FORMAT THE DATA ----
# * Table Headers ----
table_header <- table_content_tbl %>% filter(is_header) %>% pull(text)
# * Table Contents ----
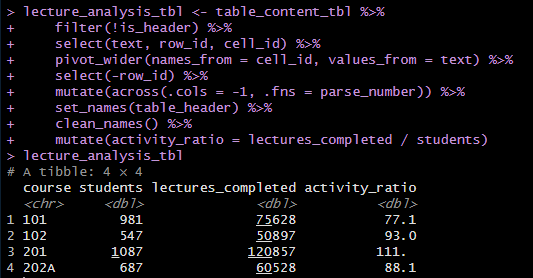
lecture_analysis_tbl <- table_content_tbl %>% filter(!is_header) %>% select(text, row_id, cell_id) %>% pivot_wider(names_from = cell_id, values_from = text) %>% select(-row_id) %>% mutate(across(.cols = -1, .fns = parse_number)) %>% set_names(table_header) %>% clean_names() %>% #小文字へ mutate(activity_ratio = lectures_completed / students)
# 4.0 VISUALIZE RESULTS ----
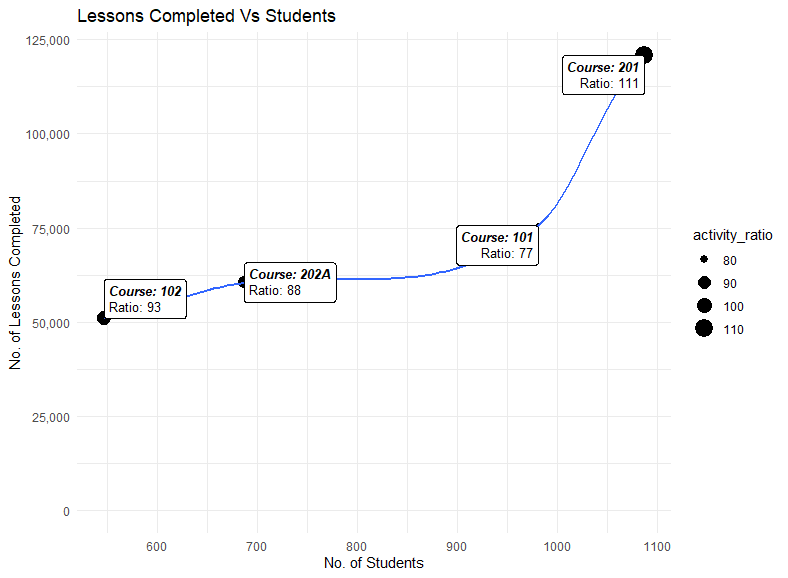
lecture_analysis_tbl %>% ggplot(aes(students, lectures_completed)) + geom_point(aes(size = activity_ratio)) + geom_smooth(method = "loess") + geom_richtext( aes(label = str_glue("___Course: {course}___<br>Ratio: {round(activity_ratio)}")), vjust = "inward", hjust = "inward", size = 3.5 ) + labs( title = "Lessons Completed Vs Students", x = "No. of Students", y = "No. of Lessons Completed" ) + scale_y_continuous(label = scales::comma) + expand_limits(y = 0) + theme_minimal()
データを視える化
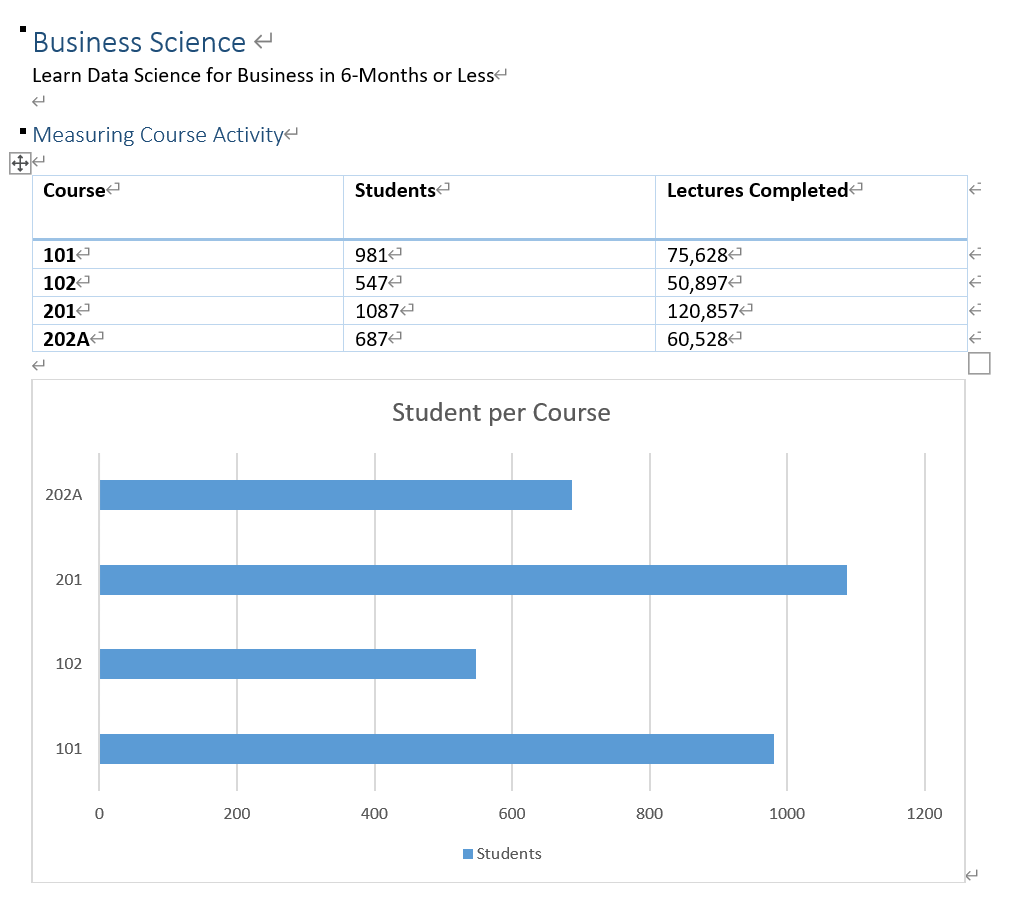
Source: https://www.business-science.io/
#Script on RstudioData Structure :

元々のデータフレーム
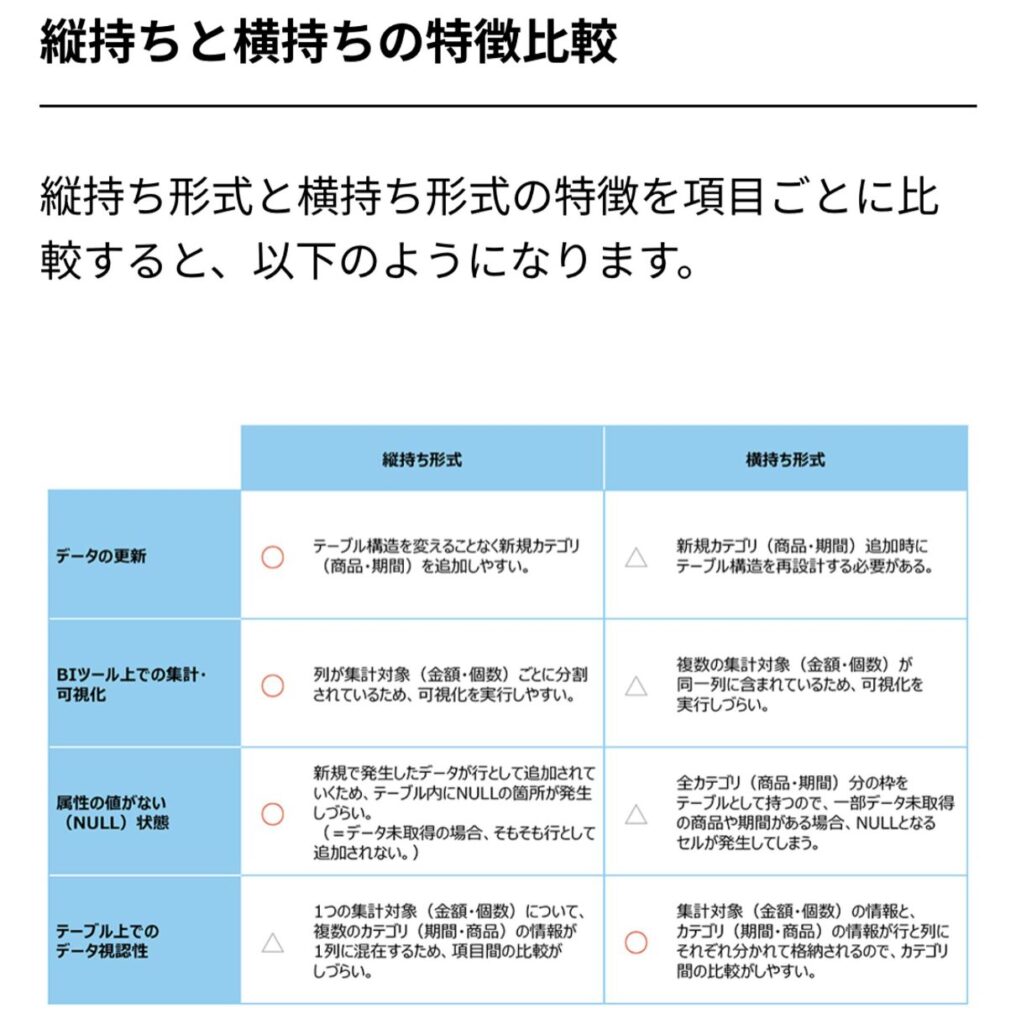
ポイントで纏め。

視える化に合わせて編集
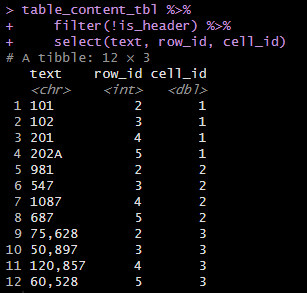
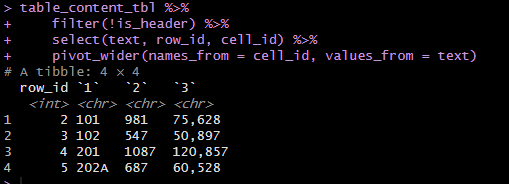
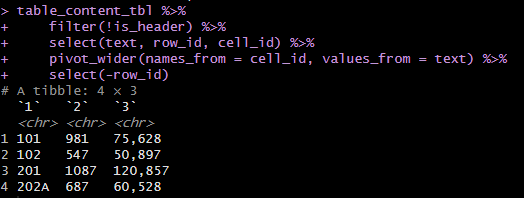
Long format(変数Xとその中身の羅列)からWide format(クロス集計表/変数Aと変数Bの中身)(row:集計対象:金額・個数、column:カテゴリ:期間・商品)へ。row_idは行数を示す。
データ型変更
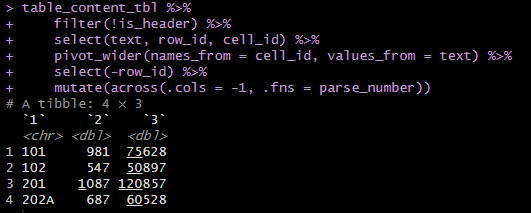
mutate(across(.cols = -1, .fns = parse_number))
- 目的:
mutateとacrossを使って、すべての数値列を数値型に変換します。.cols = -1は最初の列を除いたすべての列を指定しており、.fns = parse_numberはreadrパッケージのparse_number関数を適用して、文字列から数値を抽出・変換します。 - 効果: データの中で数値として解釈可能なものがすべて数値型に変換されます。これにより、後の解析や計算が容易になります。
acrossに関して。across()関数は、dplyrパッケージで提供されている強力なツールで、mutate(), summarise(), filter()などの関数と一緒に使用され、複数の列に対して一度に同じ操作を適用する際に便利です。across()を使うと、コードがより簡潔で可読性が高くなります。
across()の基本的な使用方法
across()の一般的な構文は次のとおりです:
mutate(across(.cols, .fns, ...)).cols: 影響を与える列を指定します。名前のパターンやインデックス、または論理値の条件で指定できます。.fns: 適用する関数を指定します。複数の関数をリストで渡すこともできます。
例: 複数の列に同じ関数を適用
1. 特定の列にlog()関数を適用
たとえば、データフレームの中の数値列に対してlog()関数を適用したい場合、以下のようにします。
library(dplyr)
# データフレームの作成
df <- data.frame( a = c(1, 2, 3, 4), b = c(10, 20, 30, 40), c = c("x", "y", "z", "w")
)
# 数値列に対してlog()を適用
df <- df %>% mutate(across(c(a, b), log))ここでは、a列とb列に対してlog()関数を適用しています。
2. すべての数値列に関数を適用
数値型の列すべてに対して操作を適用したい場合、where(is.numeric)を使うことができます。
df <- df %>% mutate(across(where(is.numeric), log))3. 名前のパターンで列を選択
特定のパターンを持つ列(例えば、”score_”で始まる列)に対して操作を適用することも可能です。
df <- df %>% mutate(across(starts_with("score_"), log))across()の活用例
あなたの例に戻ると、次のように使われています:
mutate(across(.cols = -1, .fns = parse_number)).cols = -1: 最初の列を除くすべての列を対象にしています。この指定方法は、列のインデックスで最初の列を除外することを意味します。.fns = parse_number:parse_number関数を適用しています。この関数は、文字列から数値を抽出し、数値型に変換します。
他の活用例
- 複数の関数を適用 各列に対して異なる関数を適用する場合、
list()を使って関数を渡すことができます。
df <- df %>% mutate(across(c(a, b), list(log = log, sqrt = sqrt)))これにより、a_log, a_sqrt, b_log, b_sqrtの新しい列が生成されます。
- 列名を変更して新しい列を作成
names_glueオプションを使って、新しい列の名前を指定できます。
df <- df %>% mutate(across(c(a, b), log, .names = "log_{.col}"))これにより、a列とb列の対数値がlog_aとlog_bという名前の新しい列に保存されます。
まとめ
across()関数を使うことで、複数の列に対して一括で操作を適用でき、コードが簡潔になります。これにより、データの前処理や変換が効率的かつ分かりやすく行えるようになります。使用する際は、どの列にどの操作を適用するのかを明確に指定し、処理の意図を明確にすることが重要です。