



Conductor
pivot_tb()の冒頭複数列とgt()テーブル

Visualizer
テーブル作成

Wrangler
全体像はこんな感じ
# 1.0 LIBRARIES ----
library(tidyquant)
library(tidyverse)
library(gt)
# 2.0 GET DATA ----
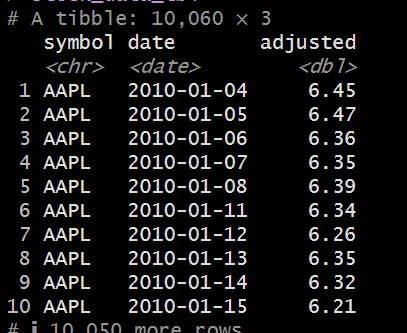
stock_data_tbl <- c("AAPL", "GOOG", "NFLX", "NVDA") %>% tq_get(from = "2010-01-01", to = "2019-12-31") %>% select(symbol, date, adjusted)
# 3.0 PIVOT TABLE - Percent Change by Year ----
# * Basics ----
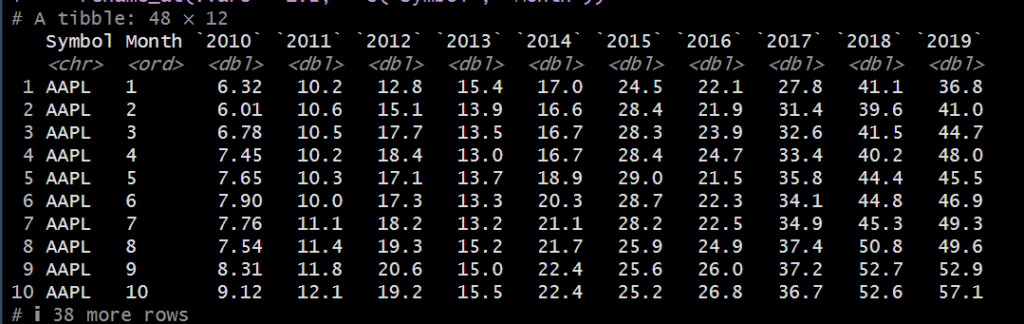
stock_data_tbl %>% pivot_table( .rows = c(~ symbol, ~ MONTH(date, label = TRUE)), # クロス集計表。行にシンボル、列に月を指定して、adjusted列の中央値を取得。 # label = TRUE は、月のラベルを取得することを指定しています。 .columns = ~ YEAR(date), .values = ~ MEDIAN(adjusted) ) %>% rename_at(.vars = 1:2, ~ c("Symbol", "Month"))
stock_data_tbl %>% pivot_table( .rows = c(~ YEAR(date), ~ MONTH(date, label = TRUE)), .columns = symbol, .values = ~ MEDIAN(adjusted) ) %>% rename_at(.vars = 1:2, ~ c("Year", "Month")) # rename_at() 関数は、列名を変更します。1列目と2列目をYearとMonthに変更。
stock_data_tbl %>% pivot_table( .columns = ~ MONTH(date, label = TRUE), # クロス集計表。列に月を指定して、adjusted列の中央値を取得。 .rows = c(~ YEAR(date), symbol), .values = ~ MEDIAN(adjusted) ) %>% rename(Year = 1)
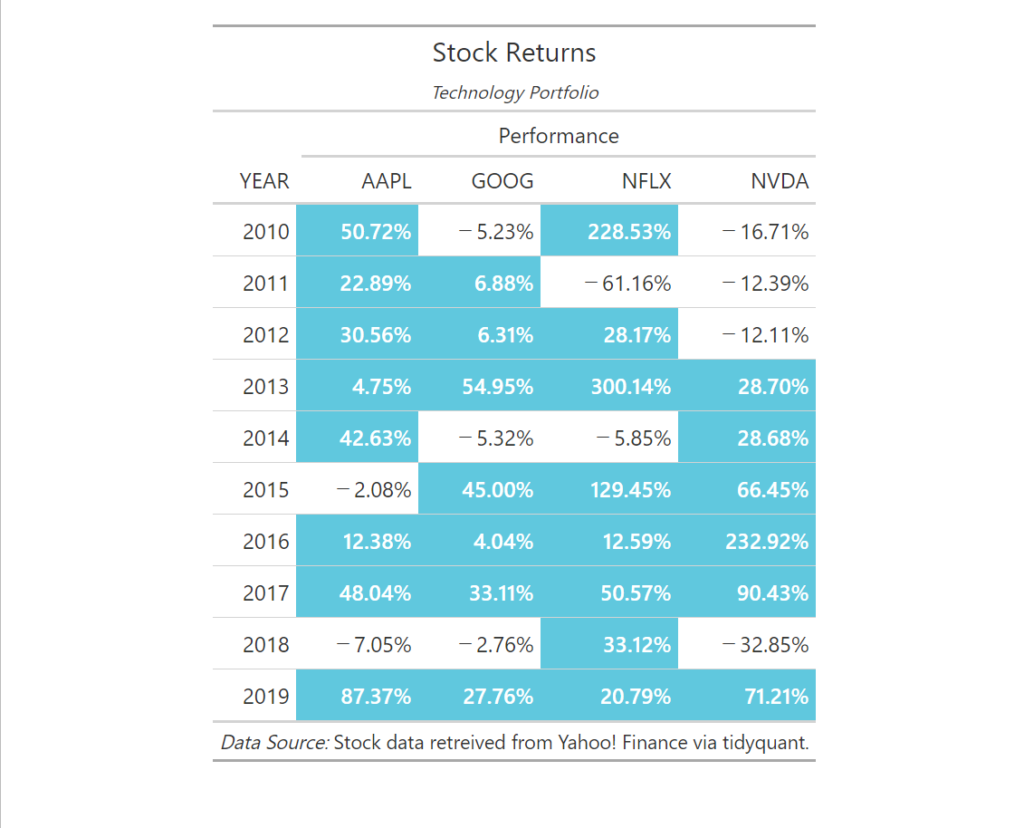
# * Percent Change by Year ----
stock_performance_tbl <- stock_data_tbl %>% pivot_table( .rows = ~ YEAR(date), .columns = ~ symbol, .values = ~ PCT_CHANGE_FIRSTLAST(adjusted) # PCT_CHANGE_FIRSTLAST() 関数は、最初と最後の値の変化率を計算します。 ) %>% rename(YEAR = 1) # rename() 関数は、列名を変更します。1列目をYEARに変更。
# 4.0 PIVOT CHARTS ----
color_fill <- "#1ecbe1" #ハイライトの色を設定
pivot_table_gt <- stock_performance_tbl %>% gt() %>% # gt() 関数は、グラフィカルテーブルを作成します。グラフィカルテーブルとは、データを視覚的に表示するテーブルです。 tab_header("Stock Returns", subtitle = md("_Technology Portfolio_")) %>% # テーブルタイトル fmt_percent(columns = vars(AAPL, GOOG, NFLX, NVDA)) %>% # fmt_percent() 関数は、パーセントをフォーマットします。 tab_spanner( # tab_spanner() 関数は、列のグループ化を行います。(エクセルの列統合) label = "Performance", columns = vars(AAPL, GOOG, NFLX, NVDA) ) %>% tab_source_note( source_note = md("_Data Source:_ Stock data retreived from Yahoo! Finance via tidyquant.") ) %>% # tab_source_note() 関数は、ソースノートを追加します。注釈。 tab_style( style = list( cell_fill(color = color_fill), #セルの色を指定色でハイライト。 cell_text(weight = "bold", color = "white") # セルの数理をボールド、白抜き。 ), locations = cells_body( columns = vars(AAPL), # 適用先の変数列名。文字列を指定。 rows = AAPL >= 0) # 適用先の行。条件を指定。 ) %>% tab_style( style = list( cell_fill(color = color_fill), cell_text(weight = "bold", color = "white") ), locations = cells_body( columns = vars(GOOG), rows = GOOG >= 0) ) %>% tab_style( style = list( cell_fill(color = color_fill), cell_text(weight = "bold", color = "white") ), locations = cells_body( columns = vars(NFLX), rows = NFLX >= 0) ) %>% tab_style( style = list( cell_fill(color = color_fill), cell_text(weight = "bold", color = "white") ), locations = cells_body( columns = vars(NVDA), rows = NVDA >= 0) )
pivot_table_gt
# 5.0 SAVING THE CHART ----
# - Requires Phantom JS
install.packages("webshot")
# install.packages("PhantomJS") R version 4.4.1 (2024-06-14 ucrt)で利用不可
pivot_table_gt %>% gtsave(filename = "006_pivot_tables/stock_returns.png") # gtsave() 関数は、グラフィカルテーブルを保存します。Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: Yahoo finance
- SQL読込: –
- CSV読込: –
- API読込 : 〇

Extractor
元々のデータフレーム
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
stock_data_tbl <- c("AAPL", "GOOG", "NFLX", "NVDA") %>% tq_get(from = "2010-01-01", to = "2019-12-31") %>% select(symbol, date, adjusted)Wrangler
視える化に合わせて編集
pivotでクロス集計表を作成。行:.rows = YEAR(date)、列:ccolumns = ~ symbol。値は.values = ~ adjusted。冒頭は1列ではなく2列指定する事が可能。
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。
- 値:data point、Feature
- Wide format:クロス集計表(横持ちデータ)、Long format:縦持ちデータ
- 情報ソースがWEBサイト(HTMLやCSS)の場合にはどこから抽出するか、が問われるので、HTMLやCSSの知識が必要(スクレイピングを実施するにせよ)。
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

