



Conductor
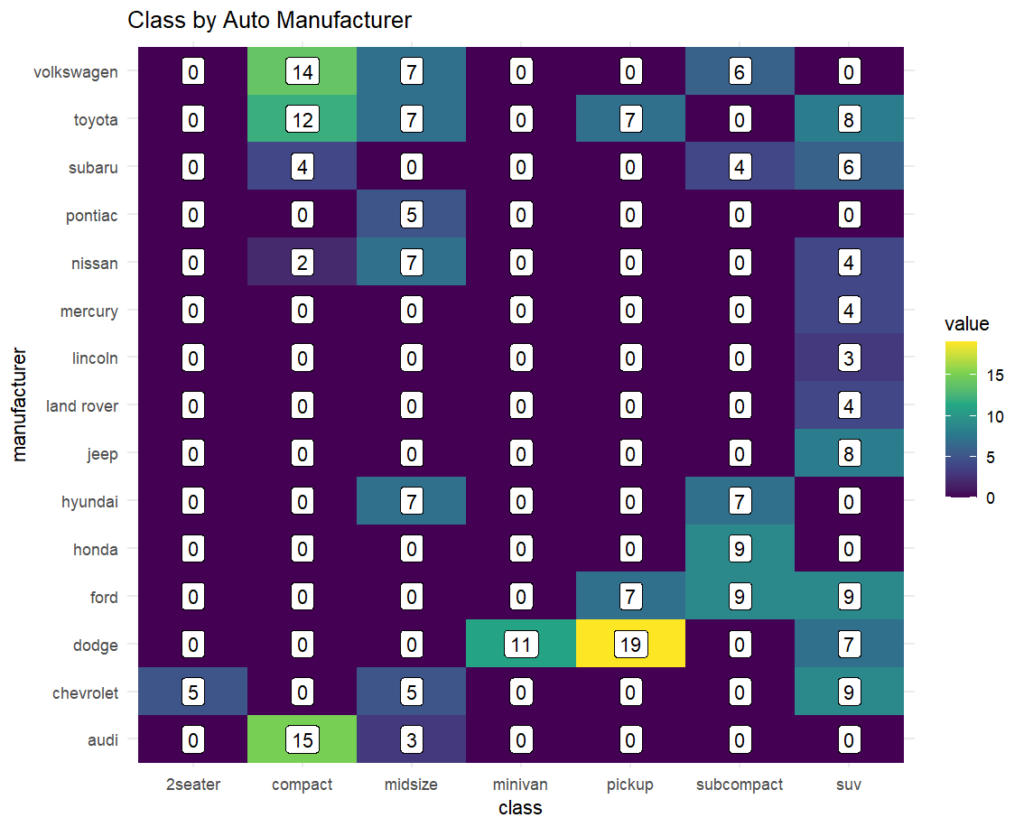
縦軸にブランド(製造)で、横軸に車種を持ってくる。中身はカウント数なので、どのブランドがどの車種をどの程度保有しているかわかる。

Visualizer
目的に応じてカラムとして集計する変数を追加していく。大小比較なら単純に降順で棒グラフ比較が分かり易いものの、どの組合せをどのブランドがカバーしているのかについては、カテゴリー変数×カテゴリー変数で整理して、①ブランドをみる、②横軸にそって攻められていない部分を視る、という比較が可能。例えば、車種別(商材の特徴別)でどの特徴が売上や利益として伸びているのか確認の上、ブランド別で車種カバレッジの割合を可視化。

Wrangler
全体像はこんな感じ
# LIBRARIES ----
library(tidyquant)
library(tidyverse)
# DATA ----
mpg
# PIVOTING DATA ----
# 1.0 Pivot Wider ----
# - Reshaping to wide format
mpg_pivot_table_1 <- mpg %>% group_by(manufacturer) %>% count(class, name = "n") %>% # class列の数をカウント。name = "n" でカウント結果をn列に格納。 ungroup() %>% pivot_wider( # wider formatに変換。横持ちデータ。クロス集計表。 names_from = class, # class列の値を列に変換 values_from = n, # n列の値を取得 values_fill = 0 # NAを0で埋める )
# 2.0 Pivot Table ----
# - Making Summary "Pivot Tables"
mpg_pivot_table_2 <- mpg %>% pivot_table( # クロス集計表を作成 .columns = class, # class列を列に変換 .rows = manufacturer, # manufacturer列を行に変換 .values = ~ n(), # n()でカウント # ~ はformulaの意味. formulaとは、関数の引数に渡す関数のこと。 fill_na = 0 # NAを0で埋める )
# - Using lists to capture complex objects
mpg %>% pivot_table( .rows = class, .values = ~ list(lm(hwy ~ displ + cyl - 1)) # ~ list(lm(hwy ~ displ + cyl - 1)) でlm()関数を使って回帰分析を行い、その結果をリストで取得. # この場合、class列の値ごとに回帰分析を行い、その結果をリストで取得している。 # このように、複雑なオブジェクトを取得する場合は、list()を使う。 # hwy ~ displ + cyl - 1 は、hwyをdisplとcylで回帰分析することを指定している。 )
# 3.0 Pivot Longer ----
# - Long format best for visualizations
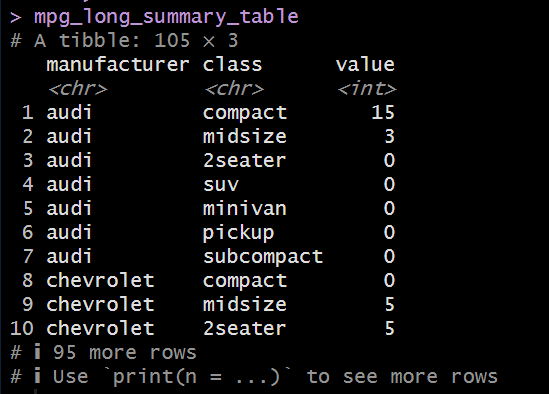
mpg_long_summary_table <- mpg_pivot_table_1 %>% pivot_longer( # long formatに変換。縦持ちデータ。 cols = compact:subcompact, # compact列からsubcompact列までを変換(class列の中身) names_to = "class", # class列に変換 values_to = "value" # value列に変換.クロス集計表の中身であったvalueはvalue列を新たにさ作成、その値を入れる。 )
mpg_long_summary_table %>% ggplot(aes(class, manufacturer, fill = value)) + # class列をx軸、manufacturer列をy軸、value列をfillで色分け geom_tile() + # タイルを描画 geom_label(aes(label = value), fill = "white") + # fill = "white" でラベルの背景色を白に指定 # aes(label = value) でラベルにvalue列の値を表示 # geom_label() でラベルを描画 scale_fill_viridis_c() + # scale_fill_viridis_c() で色をviridisに指定 # viridisはカラーパレットの一つ theme_minimal() + # theme_minimal() でテーマをminimalに指定 labs(title = "Class by Auto Manufacturer") # labs(title = "Class by Auto Manufacturer") でタイトルを指定Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: https://fueleconomy.gov/
- SQL読込: –
- CSV読込: –
- API読込 : 〇(mpg)
- rmarkdown:render()読込:- (.rmdのファイルをtemlate保存しておく必要あり)

Extractor
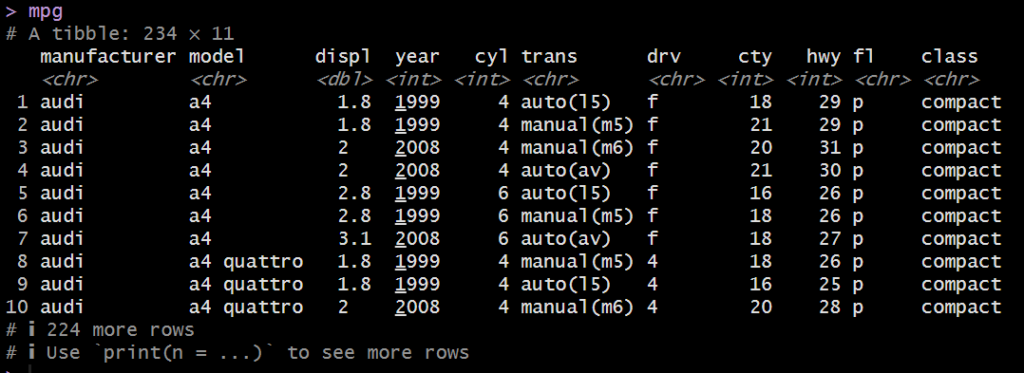
元々のデータフレーム(mpg)
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
mpgWrangler
視える化に合わせて編集
メモ
- 行 (row) :レコード、Observation
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。.xは列を指定している。
- 値:data point、Feature
- Wide format:クロス集計表(横持ちデータ)、Long format:縦持ちデータ
- 情報ソースがWEBサイト(HTMLやCSS)の場合にはどこから抽出するか、が問われるので、HTMLやCSSの知識が必要(スクレイピングを実施するにせよ)。
- レンダリング(rendering)とはコンピュータがデータを処理して画像や映像、テキストなどを表示させる技術。
- .fn(単数)と.fns(複数)はfunctionの略で無名関数。~ (tilde:チルダ) も無名関数。
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

