



Conductor
今回はArima Modelの詳しい解説はスキップ。interactiveなファイルはhtml形式で保存の上、wordpress上に展開可能である点を理解する事が目的。

Visualizer
現状、①HTML形式でローカル保存、②WordpressのメディアサーバーにHTMLファイルを保存、③カスタムHTMLのifameにHTMLリンクを埋め込み。

Wrangler
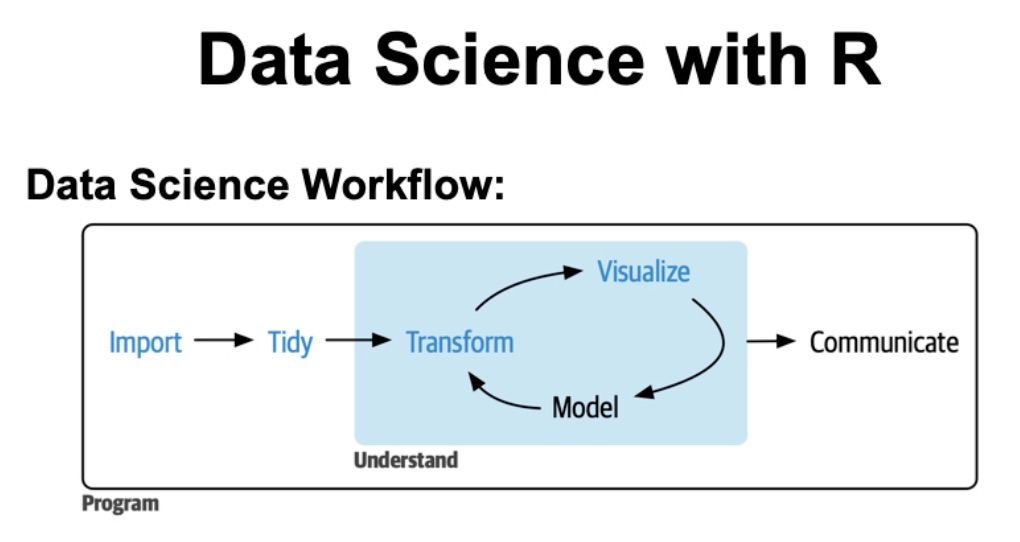
全体像はこんな感じ
# LIBRARIES ----
library(modeltime)
library(tidymodels)
library(timetk)
library(tidyverse)
# DATA ----
# - Time Series Visualization - Covered in Module 02 of DS4B 203-R Time Series Course
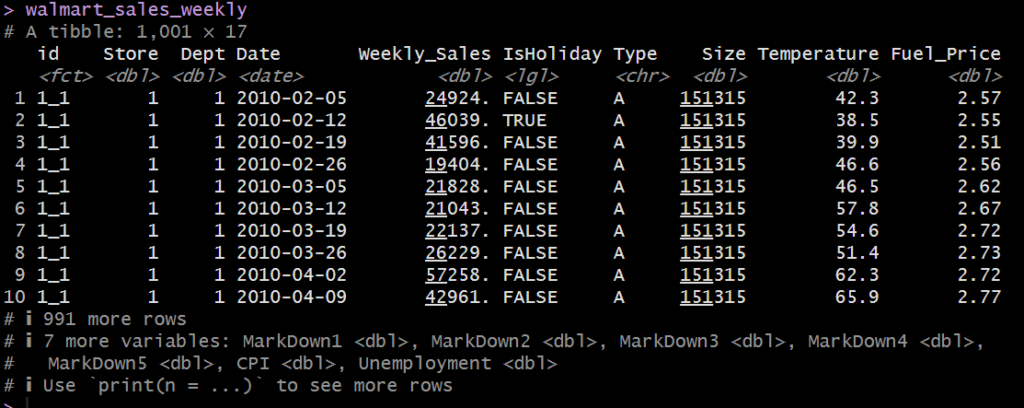
walmart_sales_weekly # this data is coming from the modeltime package.
walmart_sales_weekly %>% group_by(id) %>% plot_time_series(Date, Weekly_Sales, .facet_ncol = 2) # plot_time_series() 関数は、時系列データをプロットします。 # .facet_ncol = 2 は、2列でプロットすることを指定しています(グラフ画面)。 # Date がx軸、Weekly_Sales がy軸になっている。 # id ごとにプロットされている。
# 1.0 NESTING 101 ----
# - Nesting & Iteration - Covered in Week 5 of DS4B 101-R R for Business Course
# Nesting
data_nested <- walmart_sales_weekly %>% select(id, Date, Weekly_Sales) %>% nest(nested_column = -id) # nest() 関数は、データをネスト化します。 # -id でid列を除いたデータをネスト化している。 # ネスト化とは具体的には、データフレームの列をリストに変換することです。 # ここでは、id列を除いたデータをリストに変換しています。 # 実際には、nested_column という列にリスト(Date, Weekly_Sales列)が格納されています。
data_nested$nested_column # nested_column にはリストが格納されている。 # リストの中身は、Date, Weekly_Sales列が格納されている。
# Unnesting
data_nested %>% unnest(nested_column) # unnest() 関数は、ネスト化されたデータを元に戻します。
# 2.0 MULTIPLE ARIMA FORECASTS ----
# - Modeltime (ARIMA) - Covered in Module 8 of DS4B 203-R Time Series Course
# - Nesting, Functions, & Iteration - Covered in Week 5 of DS4B 101-R R for Business Course
# * Making Multiple ARIMA Models ----
model_table <- data_nested %>% # Map Fitted Models mutate(fitted_model = map(nested_column, .f = function(df) { # map() 関数は、リストの各要素に対して関数を適用します。 # .f = function(df) で関数を指定しています。ここでは、df にリストの各要素が格納されています。このdfはデータフレームです。 # dfという文字列は任意の文字列を記載できますか? はい、任意の文字列を記載できます。ここではdfと名付けたという事ですね。 # 実際の無名関数の役割は、{}に挟まれている内容ですね? はい、{}に挟まれている内容が無名関数の内容です。 arima_reg(seasonal_period = 52) %>% # arima_reg() 関数は、ARIMAモデルを作成します。 # seasonal_period = 52 で季節性を指定しています。52週間の季節性を指定しています。 # つまり、週次データの季節性を指定しています。 # 週次データの季節性を指定することで、季節性を考慮したARIMAモデルを作成します。 # 週次データの季節性を考慮することで、より正確な予測が可能になります。 # なぜ52週ですか?年間のデータをとる為ですか? はい、年間のデータを取るためです。 # その場合、なぜ48週間ではないのですか? 52週間のデータを取ることで、年間のデータを取ることができます。 set_engine("auto_arima") %>% # set_engine() 関数は、モデルのエンジンを指定します。 # "auto_arima" で自動ARIMAモデルを指定しています。 # 自動ARIMAモデルは、ARIMAモデルのパラメータを自動的に決定します。 # つまり、ARIMAモデルのパラメータを手動で設定する必要がなくなります。 # 自動ARIMAモデルは、ARIMAモデルのパラメータを自動的に決定するため、モデルの作成が簡単になります。 # ARIMAとは何ですか? ARIMAは、自己回帰和分移動平均モデルです。英語では、AutoRegressive Integrated Moving Average Modelです。 # 特徴は、時系列データの自己相関と季節性を考慮したモデルです。 # 自己相関とは、時系列データの過去のデータとの相関関係を指します。 # 過去のデータで何をしますか? 過去のデータを使って、未来のデータを予測します。 fit(Weekly_Sales ~ Date, data = df) # fit() 関数は、モデルを学習します。 # Weekly_Sales ~ Date でWeekly_SalesをDateで回帰分析することを指定しています。 # data = df でデータフレームを指定しています。このdfはfunction()の引数で指定しているデータフレームです。 })) %>% # Map Forecasts mutate(nested_forecast = map2(fitted_model, nested_column, .f = function(arima_model, df) { # map2() 関数は、2つのリストの要素に対して関数を適用します。 # .f = function(arima_model, df) で関数を指定しています。ここでは、arima_model にARIMAモデル、df にリストの各要素が格納されています。このdfはデータフレームです。 modeltime_table( arima_model # modeltime_table() 関数は、モデルの予測を作成します。 # arima_model にARIMAモデルを指定しています。 ) %>% modeltime_forecast( h = 52, actual_data = df ) # modeltime_forecast() 関数は、モデルの予測を作成します。 # h = 52 で52週間の予測を指定しています。 # actual_data = df でデータフレームを指定しています。このdfはfunction()の引数で指定しているデータフレームです。 # つまり、52週間の予測を作成しています。未来のですか? はい、未来のデータです。 }))
model_table
# * Unnest ----
model_table %>% select(id, nested_forecast) %>% unnest(nested_forecast) %>% group_by(id) %>% plot_modeltime_forecast(.facet_ncol = 2)Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: the modeltime package.
- SQL読込: –
- CSV読込: –
- API読込 : 〇
- rmarkdown:render()読込:- (.rmdのファイルをtemplate保存しておく必要あり)

Extractor
元々のデータフレーム
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
modeltime packageWrangler
視える化に合わせて編集

メモ
- 行 (row) :レコード、Observation、観測値(サンプル数)
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。.xは列を指定している。obs = number of observatins.
- 値:data point、Feature
- Wide format:クロス集計表(横持ちデータ)、Long format:縦持ちデータ
- 情報ソースがWEBサイト(HTMLやCSS)の場合にはどこから抽出するか、が問われるので、HTMLやCSSの知識が必要(スクレイピングを実施するにせよ)。
- レンダリング(rendering)とはコンピュータがデータを処理して画像や映像、テキストなどを表示させる技術。
- .fn(単数)と.fns(複数)はfunctionの略で無名関数。~ (tilde:チルダ) も無名関数。
環境設定
- HTML形式のファイルが「file:///C:/Users/XXXXX/・・・」で保存されている場合、ローカルで保存されている状態。HTMLファイルをウェブサーバー(WordPressサイト)にアップロードする必要があり。
- RのバージョンとRtoolsのバージョンは合わせる必要性がある。Rstudioは最新版でも問題なし。
- 初期設定の3点セット:R, Rstudio, Rtools
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

