



Conductor
論点が多いので、2点に絞る。①group_split()で各データフレームをリストの形式で保持し、各データフレームはそのままtibble型として保持できる。②glanceで統計量の変数(r.squared, adj.r.squared, p.value, nobs)を追加可能。

Visualizer
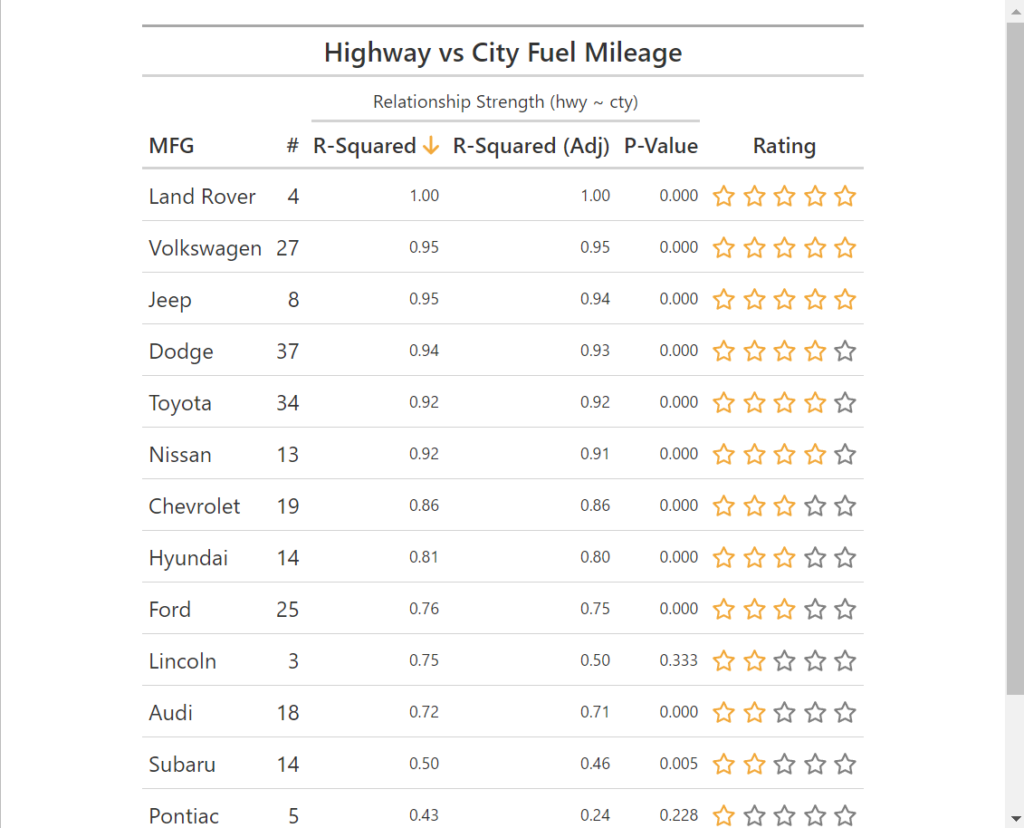
gt()を利用してデータテーブルとして情報を纏める。

Wrangler
全体像はこんな感じ
# LIBRARIES ----
library(tidyquant)
library(tidyverse)
library(broom)
# devtools::install_github("rstudio/fontawesome")
library(gt)
library(fontawesome)
library(htmltools)
# DATA ----
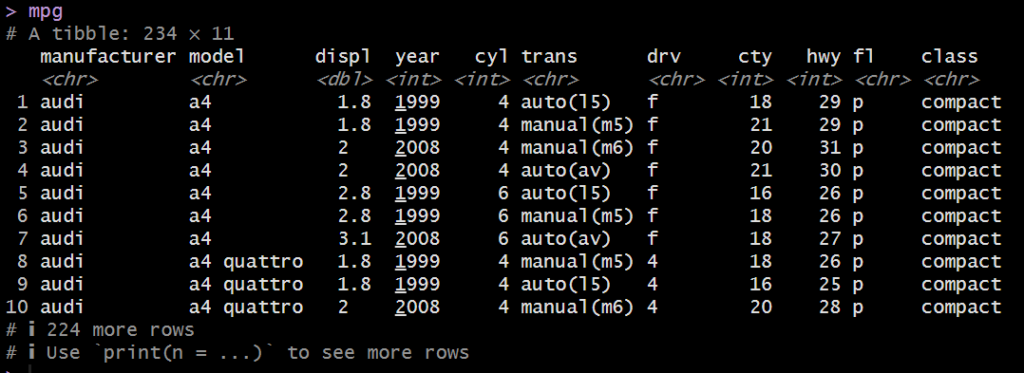
mpg
# 1.0 GROUP SPLIT ----
# - Turns a grouped data frame into an list of data frames (iterable)
# - Iteration & functions - Covered in Week 5 of DS4B 101-R
# Group Split
mpg %>% mutate(manufacturer = as_factor(manufacturer)) %>% # as_factor()でmanufacturer列をfactor型に変換 # factor型に変換することで、group_by()でグループ化した際に、グループごとにデータを分割しやすくなる。 group_by(manufacturer) %>% group_split() # group_split()でグループごとにデータを分割し、リスト形式で返す。 # この場合、manufacturer列でグループ化しているので、manufacturerごとにデータを分割している(各データはtibble型)。
# We can now iterate with map()
mpg %>% mutate(manufacturer = as_factor(manufacturer)) %>% group_by(manufacturer) %>% group_split() %>% map(.f = function(df) { # map()でリストの各要素に対して関数を適用 lm(hwy ~ cty, data = df) # ここでは、リストの各要素(データフレーム)に対してlm()関数を適用している。 # lm()関数は、線形回帰モデルを作成する関数。 # hwy ~ cty でhwyをctyで回帰分析することを指定している。 # data = df でデータフレームを指定している。 })
# 2.0 POWER OF BROOM ----
# - Tidy up our linear regression metrics with glance()
# - Modeling & Machine Learning - Covered in Week 6 of DS4B 101-R Course
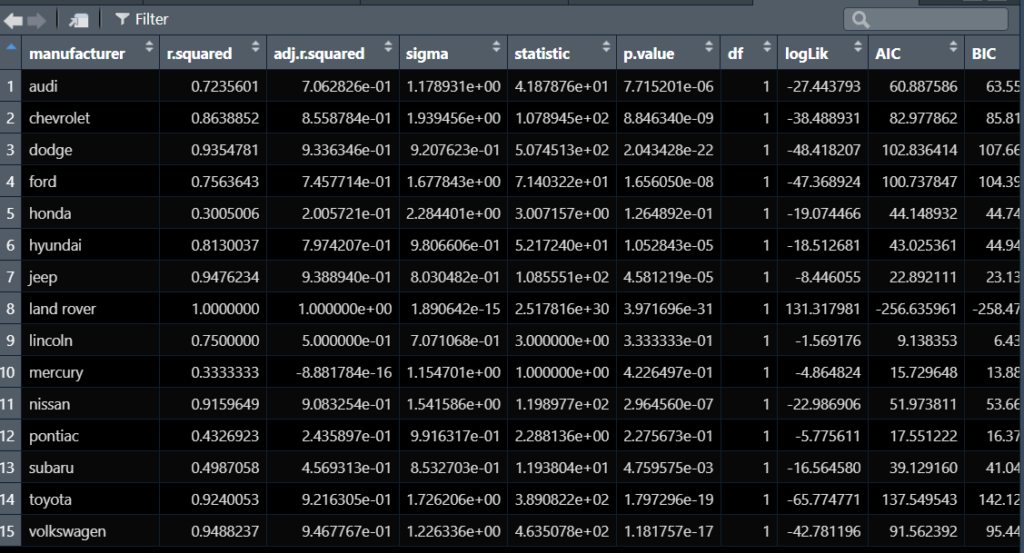
hwy_vs_city_tbl <- mpg %>% mutate(manufacturer = as_factor(manufacturer)) %>% group_by(manufacturer) %>% group_split() %>% map_dfr(.f = function(df) { lm(hwy ~ cty, data = df) %>% glance() %>% # glance()で線形回帰モデルの統計量を取得 # 具体的には、r.squared, adj.r.squared, p.valueなどの統計量を取得している。 add_column(manufacturer = unique(df$manufacturer), .before = 1) # add_column()でデータフレームに列を追加 # manufacturer列を追加している。 # unique(df$manufacturer) でdfのmanufacturer列のユニークな値を取得している。 # .before = 1 でmanufacturer列を先頭に追加している。 })
# 3.0 SUPER AWESOME TABLE WITH GT PACKAGE ----
# Source: https://themockup.blog/posts/2020-10-31-embedding-custom-features-in-gt-tables/
rating_stars <- function(rating, max_rating = 5) { # Function to create star ratings # rating: rating value # max_rating: maximum rating rounded_rating <- floor(rating + 0.5) # always round up # floor()で小数点以下を切り捨て、+0.5して四捨五入している。 # これにより、ratingの値を四捨五入している。 # 例えば、ratingが3.4の場合、3.4 + 0.5 = 3.9 となり、floor()で3に切り捨てられる。 stars <- lapply(seq_len(max_rating), function(i) { # lapply()で1からmax_ratingまでの数値に対して関数を適用 # ここでは、1からmax_ratingまでの数値に対して、以下の処理を行っている。 # seq_len(max_rating) で1からmax_ratingまでの数値を生成している。 # 生成した数値に対して、以下の処理を行っている。 if (i <= rounded_rating) { fontawesome::fa("star", fill= "orange") } else { fontawesome::fa("star", fill= "grey") } }) # iがrating以下の場合は、星を黄色で表示し、それ以外は灰色で表示する。 # これにより、ratingの値に応じて星の表示を変えている。 label <- sprintf("%s out of %s", rating, max_rating) # sprintf()で文字列をフォーマット. フォーマットとは、文字列の中に変数を埋め込むこと。 # ratingとmax_ratingを表示するための文字列を作成している。 # 例えば、ratingが3.4、max_ratingが5の場合、"3.4 out of 5" となる。 div_out <- div(title = label, "aria-label" = label, role = "img", stars) # div()でdiv要素を作成. divとは、HTMLの要素の一つで、他の要素をグループ化するために使用される。 # title, aria-label, role, starsを指定してdiv要素を作成している。 # title: ツールチップに表示されるテキスト # aria-label: 要素の役割を説明するための属性 # role: 要素の役割を指定するための属性 # stars: 星の表示 as.character(div_out) %>% # as.character()でdiv_outを文字列に変換 gt::html() # gt::html()でHTML要素を作成
}
hwy_vs_city_tbl %>% select(manufacturer, nobs, r.squared, adj.r.squared, p.value) %>% mutate(manufacturer = str_to_title(manufacturer)) %>% # str_to_title()で文字列をタイトルケースに変換 mutate(rating = cut_number(r.squared, n = 5) %>% as.numeric()) %>% # cut_number()で数値を指定した数のグループに分割 # ここでは、r.squaredを5つのグループに分割している。 # as.numeric()で数値型に変換 # これにより、r.squaredの値を5つのグループに分割している。 # 例えば、r.squaredが0.2の場合、1に分類される。# 0.4の場合、2に分類される。 # 分割基準は、0.2, 0.4, 0.6, 0.8。どのように分割されるかは、cut_number()関数のnで指定している。5等分の場合は、n=5。 mutate(rating = map(rating, rating_stars)) %>% # map()でrating列にrating_stars()関数を適用 arrange(desc(r.squared)) %>% # arrange()でデータを並び替え # desc()で降順に並び替え gt() %>% # gt()でgtオブジェクトを作成. gtオブジェクトとは、表を作成するためのオブジェクト。 tab_header(title = gt::md("__Highway vs City Fuel Mileage__")) %>% # tab_header()で表のヘッダーを設定 tab_spanner( label = gt::html("<small>Relationship Strength (hwy ~ cty)</small>"), columns = vars(r.squared, adj.r.squared, p.value) ) %>% # tab_spanner()で列のグループ化を行う # Relationship Strength (hwy ~ cty) というラベルを設定して、r.squared, adj.r.squared, p.valueをグループ化している。 # vars()で列を指定 fmt_number(columns = vars(r.squared, adj.r.squared)) %>% # fmt_number()で数値をフォーマット fmt_number(columns = vars(p.value), decimals = 3) %>% # 小数点以下3桁まで表示 tab_style( style = cell_text(size = px(12)), locations = cells_body( columns = vars(r.squared, adj.r.squared, p.value)) ) %>% # tab_style()でスタイルを設定 # cell_text()でセルのテキストのスタイルを設定 cols_label( manufacturer = gt::md("__MFG__"), nobs = gt::md("__#__"), r.squared = gt::html(glue::glue("<strong>R-Squared ", fontawesome::fa("arrow-down", fill = "orange"), "</strong>")), adj.r.squared = gt::md("__R-Squared (Adj)__"), p.value = gt::md("__P-Value__"), rating = gt::md("__Rating__") ) # cols_label()で列のラベルを設定 # gt::md()でマークダウンを設定 # gt::html()でHTMLを設定 # glue::glue()で文字列を結合 # fontawesome::fa()でフォントアイコンを設定 # fill = "orange"でアイコンの色をオレンジに設定 # これにより、列のラベルを設定している。 # 例えば、manufacturer列のラベルを"MFG"として設定している。 # R-Squaredのラベルを設定している。 # その他の列のラベルを設定している。 # これにより、表の列のラベルを設定している。Raw data / Wrangling / Feature Engineering(抽出~整形)
- Source: https://fueleconomy.gov/
- SQL読込: –
- CSV読込: –
- API読込 : 〇(mpg)
- rmarkdown:render()読込:- (.rmdのファイルをtemplate保存しておく必要あり)

Extractor
元々のデータフレーム(mpg)
Wrangler
Loading
# Script on Rstudio
# Tips: 読み込み先のファイルは「記載するpath名の始まり」からWorking Directoryとして設定する必要性がある。
mpgWrangler
視える化に合わせて編集
メモ
- 行 (row) :レコード、Observation、観測値(サンプル数)
- 列 (column):特徴量、変数、次元数、次元の削減(Dimensionality Reduction): 高次元データを少ない次元に圧縮し、モデルの効率を上げるための手法。.xは列を指定している。obs = number of observatins.
- 値:data point、Feature
- Wide format:クロス集計表(横持ちデータ)、Long format:縦持ちデータ
- 情報ソースがWEBサイト(HTMLやCSS)の場合にはどこから抽出するか、が問われるので、HTMLやCSSの知識が必要(スクレイピングを実施するにせよ)。
- レンダリング(rendering)とはコンピュータがデータを処理して画像や映像、テキストなどを表示させる技術。
- .fn(単数)と.fns(複数)はfunctionの略で無名関数。~ (tilde:チルダ) も無名関数。
参考リンク
- Script事例:https://www.business-science.io/
- Rデータの種類:https://ebreha.com/__trashed/

